・テーマ「機械学習を用いた読唇精度の向上」
Improvement of the lip reading system using by machine learning
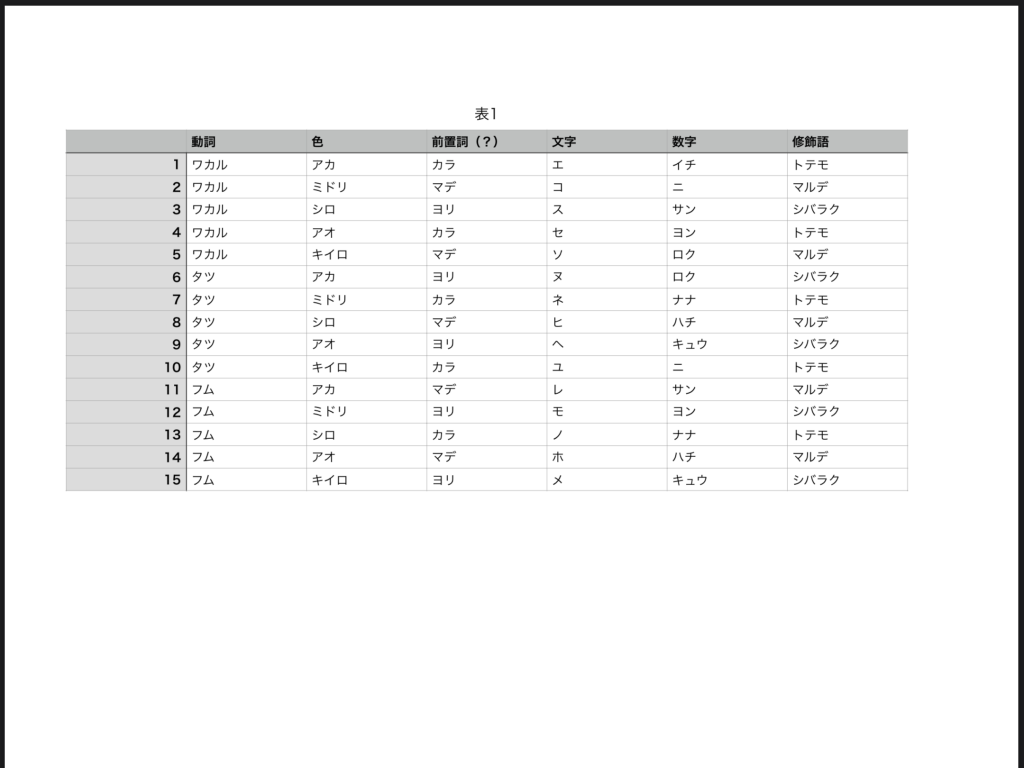
11人に15通り発音してもらい、その内フレーム毎の正解ラベルを5人まで貼った。ラベルを貼る作業を続けながら発話者を増やしてデータを集めていきたい。

・テーマ「機械学習を用いた読唇精度の向上」
Improvement of the lip reading system using by machine learning
11人に15通り発音してもらい、その内フレーム毎の正解ラベルを5人まで貼った。ラベルを貼る作業を続けながら発話者を増やしてデータを集めていきたい。
https://github.com/sailordiary/LipNet-PyTorch DL-BOXのCUDAが9になっていたので動かせました。時間がかかりそうだったのでGPUが2枚以上使えないか色々調べたがRNNを含むコードには不向きらしい。。。
https://github.com/osalinasv/lipnet Kerasで実装されてる方も動いたので精度が良い方を使いたい。どちらもデータセットはGRIDコーパスhttp://spandh.dcs.shef.ac.uk/gridcorpus/を用いた。
自分で日本語のデータセットを作るためにもう一度LipNetに関する論文に目を通した。https://www.ams.giti.waseda.ac.jp/data/pdf-files/2019_asami_bt.pdf https://arxiv.org/abs/1611.01599
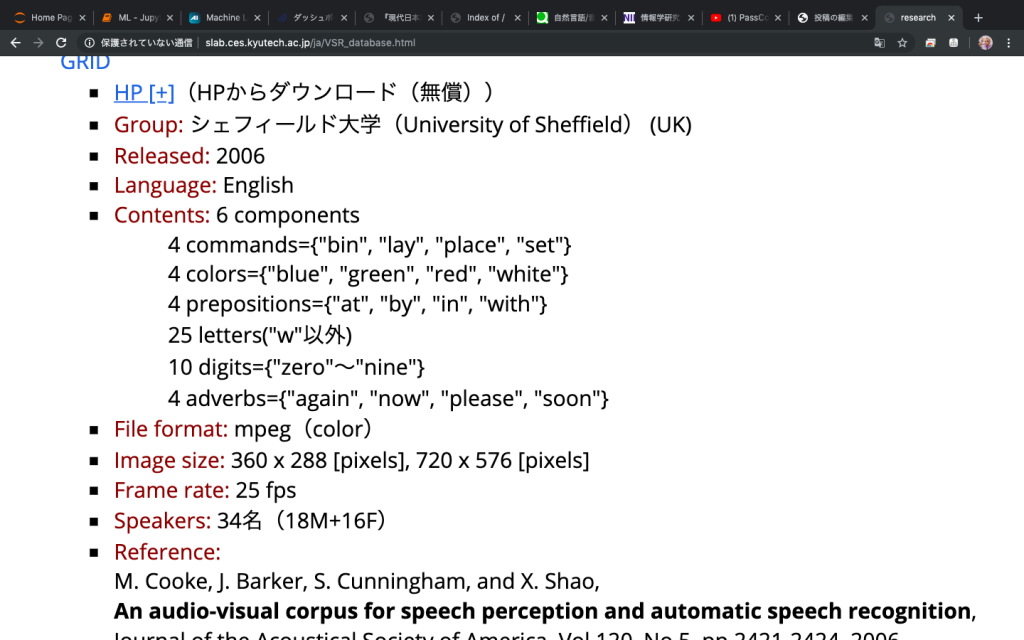
使われてるデータセットのGRIDはcommand + color + preposition + letter + digit + adverb で構成されている。(silは無声期間)
テーマ:機械学習を用いた読唇精度の向上
githubにあるLipNetのコードを動かそうとした.
https://github.com/rizkiarm/LipNet:知識不足で実装できず
https://github.com/sailordiary/LipNet-PyTorch:Macでは動いたが1epochが17日となったため、DL-BOXで動かそうとしたがCUDA8がPytorch1以上に対応しておらず断念。
https://github.com/osalinasv/lipnet:tensorflow1.1なのでDL-BOXでも動かせそう。前処理に48時間くらいかかりそうなので待ってます。(11/11の深夜に始めた)
(追記)CUDA9になってました
テーマ:機械学習を用いた読唇精度の向上
dlibを用いてデータセットの前処理(動画から唇だけを取り出す)の練習をした。用いたデータセット(GRID)http://spandh.dcs.shef.ac.uk/gridcorpus/(LipNetに用いられていたもの) gitlabに使ったプログラムをあげた。

↑GRIDの動画
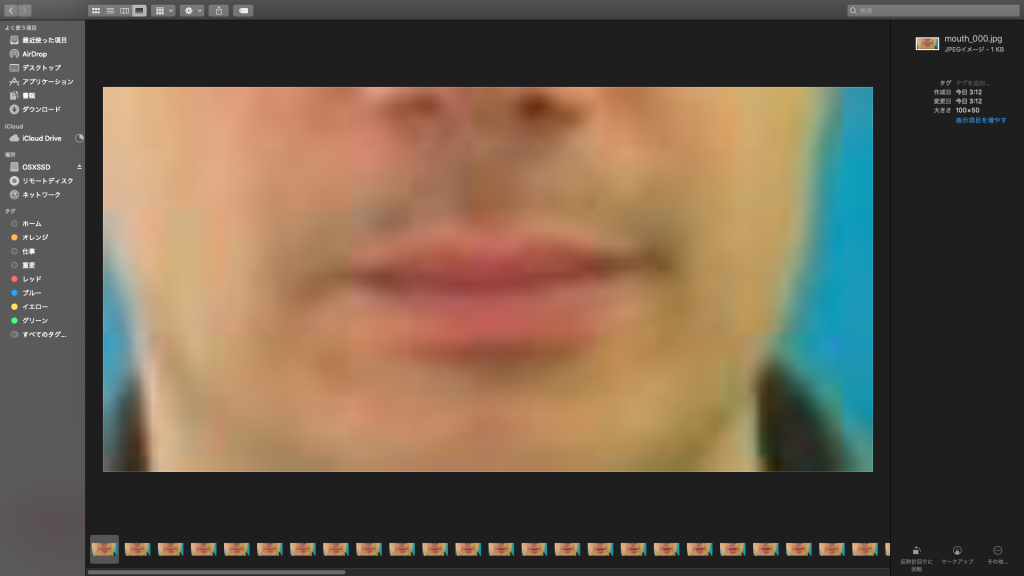
↑mpgを70枚のjpgにした
↑自分で撮った動画でもやってみた
・来週の目標:画質が荒くても良いのかまだわからないので、プログラムを動かして検証してみる
テーマ:機械学習を用いた読唇精度の向上
先週のゼミで指摘された通り、斎藤先生のプログラムの中身を調べたhttps://github.com/kyutech-saitoh/3D-CNN-for-Lip-Reading-Challenge2019 学習用データとテストデータのラベルはテキストファイルによって紐付けされていた。自分で少ないデータセットを用いてプログラムを書き換えて実行しようとしたが、1つのフォルダの中に発話シーンの画像が数十枚あり、そのフォルダごとに正解ラベルがあって挫折したので、斎藤先生のプログラムを活用したい。データセット(SSSDhttp://www.slab.ces.kyutech.ac.jp/SSSD/index_ja.html)に用いた画像は、Dlibを用いて唇を抽出しているみたい。
LipNet(https://github.com/rizkiarm/LipNet)の中身を知る前にgit cloneして動かせるか確認したが、pip install -e .する際にgccが入ってないみたいなエラーが3件くらい出て検索したところXcodeを入れれば治ると書いてあったが、入れてみたところ変化なし。
ディープラーニングボックスに接続してPythonの仮想環境を構築してKerasのverを合わせた。
基本情報の試験を受けた。
・来週の目標:dlibを用いて唇の特徴点の抽出を行う
SSSDをもらった斎藤先生からもらったサンプルコードを動かそうと思ったが、とても遅いのでグーグルのGPUサービスを使うためにデータセットをpickleに変換中。https://github.com/kyutech-saitoh/3D-CNN-for-Lip-Reading-Challenge2019
オープンキャンパスで高校生と話した。Pythonの練習としてCで書かれているものをPythonで書き直した。