After reading some paper, I find that most paper are depth-supervised or a combination of depth, pose and stereo. And I don't find any paper only using pose-supervised.
The reason why not only using pose-supervised is that only considering large intensity gradient area will produce better results. And area with less texture will cause … Continue Reading ››
reproduce the code of paper(DepthNet), and upload to https://mountain.elcs.kyutech.ac.jp/zhou/convlstm.git
problems: there is no stride in FC_LSTM and LSTM, but it exist in CNN. I used interpolation to process C of pre_layer, but it may not be the best method. Maybe this is a point that can be improved in the future.
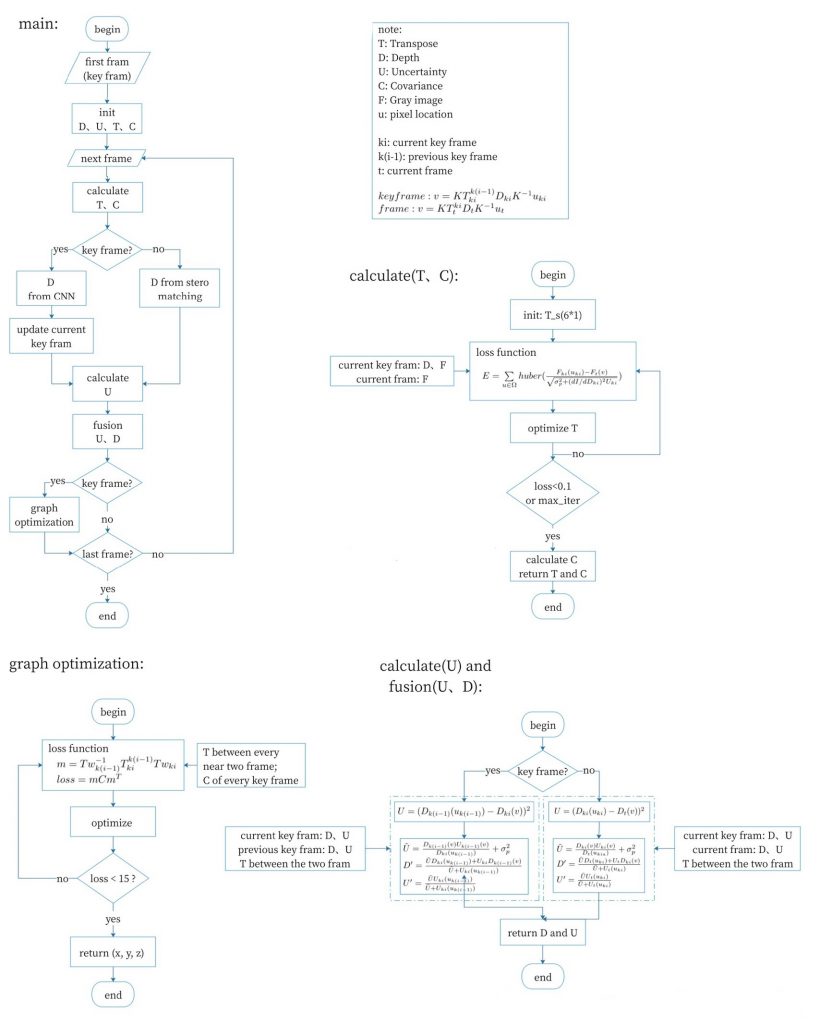
Reproduce the code of each part in the paper(CNN_SLAM) based on pytorch, and upload to https://mountain.elcs.kyutech.ac.jp/zhou/cnn_slam/-/tree/master/zs_cnn_slam .The workflow of each part is show as bellow: