テーマ:機械学習を用いた読唇精度の向上
githubにあるLipNetのコードを動かそうとした.
https://github.com/rizkiarm/LipNet:知識不足で実装できず
https://github.com/sailordiary/LipNet-PyTorch:Macでは動いたが1epochが17日となったため、DL-BOXで動かそうとしたがCUDA8がPytorch1以上に対応しておらず断念。
https://github.com/osalinasv/lipnet:tensorflow1.1なのでDL-BOXでも動かせそう。前処理に48時間くらいかかりそうなので待ってます。(11/11の深夜に始めた)
(追記)CUDA9になってました
今週の進捗
- 歩行者の再識別(ReID)-Deep learning person re-identification in PyTorch, 異なるデータセットで個別にトレーニングとテストを行う(s- dukemtmcreid /-t- market1501)。
- 張先生の指導の下、実験の別の部分が始まりました:
- (1)環境の構築を実行し、簡単なゲームアプリを実装することにより、開発プロセスを一般的に理解します(図 1、2、3)。
- (2)kivyとpygameを使用して、カメラから撮影した写真を表示します(図 4、5)。
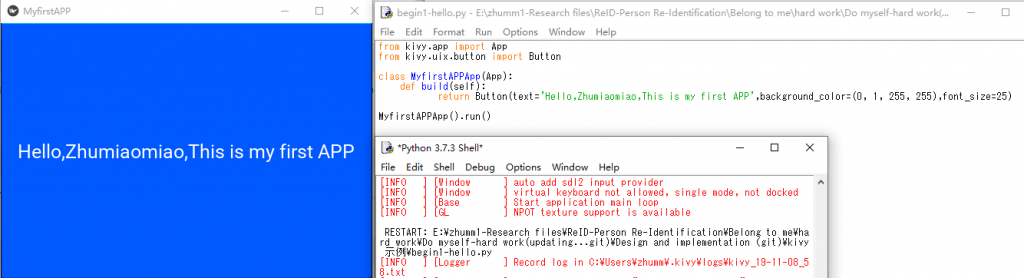 図 1.私の最初の App
図 1.私の最初の App
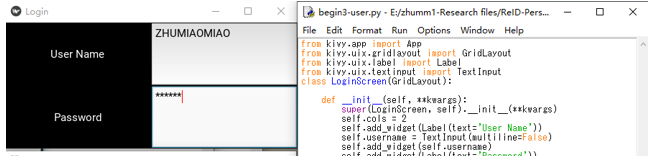 図2. ログインインターフェイス(基本機能はまだ実装されていません
図2. ログインインターフェイス(基本機能はまだ実装されていません
![]() Continue Reading ››
Continue Reading ››
財前:商品のトリミングを研究のキーポイントとする。現場でいくつかの商品を手に取る写真を取得し、商品の切り出しアイディアを考える。ソフトでするか、ハード(レンズの焦点距離固定か)を再考する。眼の不自由の人のプライドを考えて手法を考案する。
水戸:Dlibを使用し、顔の向きが検出できた。顔の方向ベクトルと瞳の座標を組み合わせて、視線位置を検出するアルゴリズムの作成を行う予定。投稿にフローチャットを追加してください。
五十君:日本に売られている商品名を単語分散表現で表す場合、いっぱんてきな言葉の単語表現との差があれば、商品名を単語分散表現のマップを作成する。
白石:機械学習VSMに入力するためのデータセット(NPZファイル)を画像から作成する。完成次第連絡。
二石:偏光フィルムでQRCodeを作成し、日光、夜間での検出実験を行う、結果次第で次へ進む。
北原:lipNetの学習データセットの作り方が分かったので、言葉数は日本語の50音を網羅したセットを用意する、話者は20名を目標とする。オリジナルLipNetを一回動かす!
テーマ:機械学習を用いた読唇精度の向上
dlibを用いてデータセットの前処理(動画から唇だけを取り出す)の練習をした。用いたデータセット(GRID)http://spandh.dcs.shef.ac.uk/gridcorpus/(LipNetに用いられていたもの) gitlabに使ったプログラムをあげた。

↑GRIDの動画
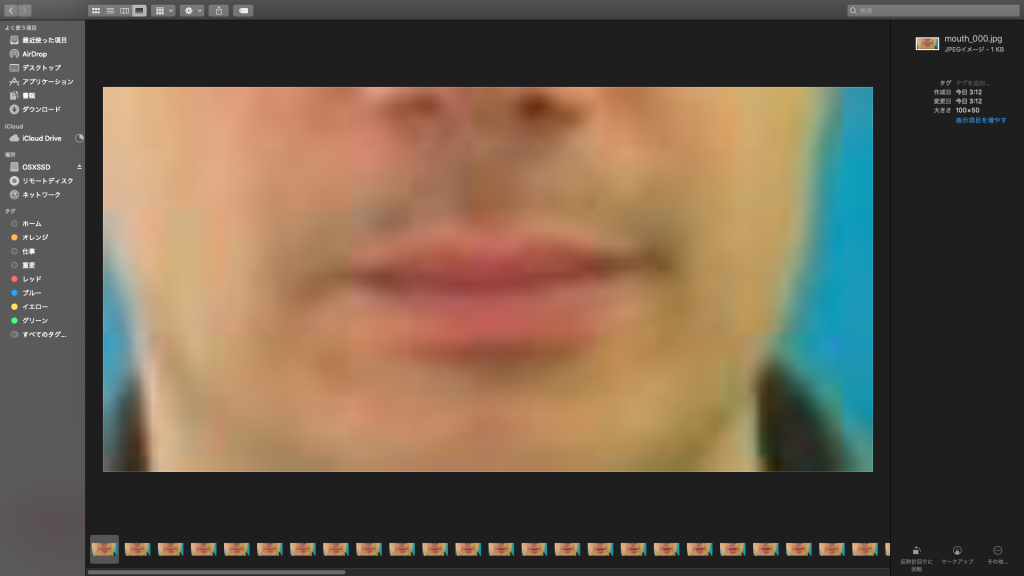
↑mpgを70枚のjpgにした
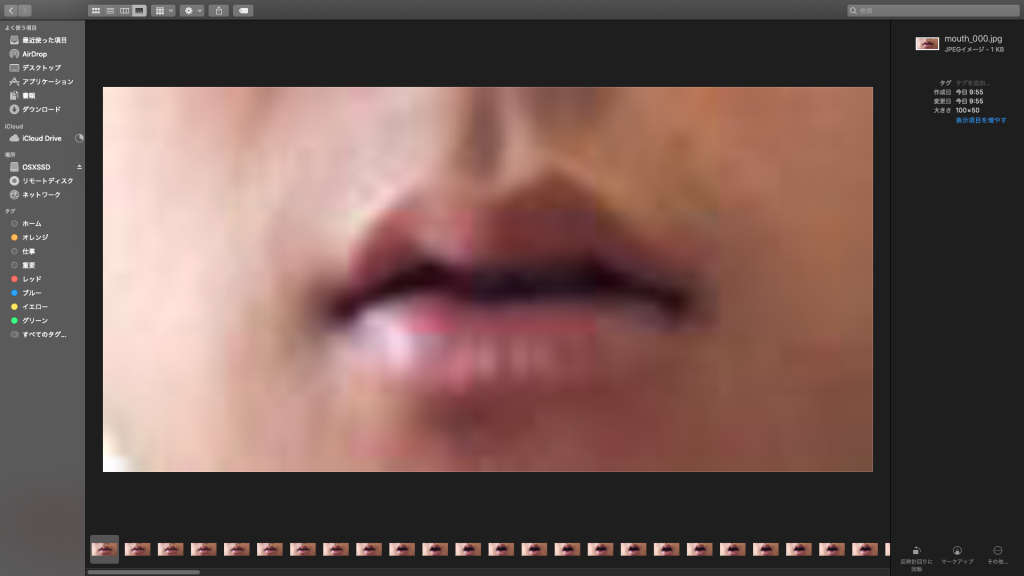
↑自分で撮った動画でもやってみた
・来週の目標:画質が荒くても良いのかまだわからないので、プログラムを動かして検証してみる
前回は認識できなかった撮影画像からのQRコードの読み取りができた。
画像が大きすぎると認識ができないようなのでリサイズし、二値化などの処理を施すことで読み取れた。しかし、認識精度があまり高くなく、かなり鮮明なQRでも読み取れず光の当たり具合や逆光などで全ての認識がうまくいくわけではなかった。
来週の予定:QRの認識精度が高いものがないか(Zbar)、画像によって補正の具合を調整できないか検討する。
黒点とサビの画像を全て60×60にリサイズした。
↓を参考にラベル付けをしようとしたがよく分からなかったので、今週できるようにする。
https://qiita.com/ufoo68/items/69b855b3b757c65ac139
ラベル付けしたらSVMで試す。
テーマ「文字認識を用いた買い忘れ防止案」
今週の進捗
①fastTextをインストールすることができた。
②マッチング方法について、再度考え直し、レシートから読み取れた商品名がどの種類の食品なのかをfastTextを用いてクラス分類できると一番良いと考えた。
研究相談
・上記の②のことを実現するため、学習用データをどうしたらよいかが現状分かりません。色々な食品の品種名を一覧でまとめてくれているサイト(例、お米の品種一覧:https://ichiranya.com/technology/002-rice.php)があり、URLを指定すればそこから記事をピックアップして学習させることができることは、こちらのサイト(https://www.pytry3g.com/entry/gensim-word2vec-tutorial)から分かったのですが、こちらのサイトの中でのkeywordに当たる部分は、自分の場合はどうしたら良いかが分かりません。
dlibを用いた顔検出において、左右の瞳の座標を得るように先週のプログラムを改良した。また、その2つの座標を結んだ線分の中点の座標を得ようとプログラムを書き換えたがうまくいかなかった。(図1)
調べた結果Openfaceを用いると顔の方向ベクトルを検出できるようなのでプログラムを実行してみた。(図2)顔の向きにより大まかな視線の方向を推定し、瞳の座標により視線位置の特定ができるといいかなと思っている。
今後は、顔の方向ベクトルと瞳の座標を組み合わせて、視線位置を検出するアルゴリズムの作成を行う。アルゴリズムに関しては思考中です。
 図1 フレームレートと左右の瞳座標を表示させた
図1 フレームレートと左右の瞳座標を表示させた
 図2 顔の方向ベクトルを表示している
図2 顔の方向ベクトルを表示している
判別する物体をトリミングする手法について2つの方法で試みた
①親指を検出し、そこからトリミングする
 親指を検出
親指を検出
 親指の周りをトリミング
親指の周りをトリミング
机を変えたり、物体を持ったら識別できないのでもっと学習用の画像を増やすことが必要。
②動画中の動体を検出し、背景を除去し動体だけを取り出す
 前の瞬間との差分を検出し動いた部分を白色で表示
前の瞬間との差分を検出し動いた部分を白色で表示
全員
仮屋:GPの関数を追加し、再実験を行った。修論を一段まとめてから、深く研究を継続する。
藤島:RaspBerry Pi 不調、フォーマットし直したものを渡し、再度構築する。
赤瀬:修論作成に専念、現在のクラスファイルに年号の記載が平成のままになったいるようで、これをのちほど修正する。
中尾:DlibをRaspberry PIにインストールし、これから試す。LED点灯回路を作る。
Stay Hungry, Stay Foolish!
