財前:商品のトリミングを研究のキーポイントとする。現場でいくつかの商品を手に取る写真を取得し、商品の切り出しアイディアを考える。ソフトでするか、ハード(レンズの焦点距離固定か)を再考する。眼の不自由の人のプライドを考えて手法を考案する。
水戸:Dlibを使用し、顔の向きが検出できた。顔の方向ベクトルと瞳の座標を組み合わせて、視線位置を検出するアルゴリズムの作成を行う予定。投稿にフローチャットを追加してください。
五十君:日本に売られている商品名を単語分散表現で表す場合、いっぱんてきな言葉の単語表現との差があれば、商品名を単語分散表現のマップを作成する。
白石:機械学習VSMに入力するためのデータセット(NPZファイル)を画像から作成する。完成次第連絡。
二石:偏光フィルムでQRCodeを作成し、日光、夜間での検出実験を行う、結果次第で次へ進む。
北原:lipNetの学習データセットの作り方が分かったので、言葉数は日本語の50音を網羅したセットを用意する、話者は20名を目標とする。オリジナルLipNetを一回動かす!
テーマ:機械学習を用いた読唇精度の向上
dlibを用いてデータセットの前処理(動画から唇だけを取り出す)の練習をした。用いたデータセット(GRID)http://spandh.dcs.shef.ac.uk/gridcorpus/(LipNetに用いられていたもの) gitlabに使ったプログラムをあげた。

↑GRIDの動画
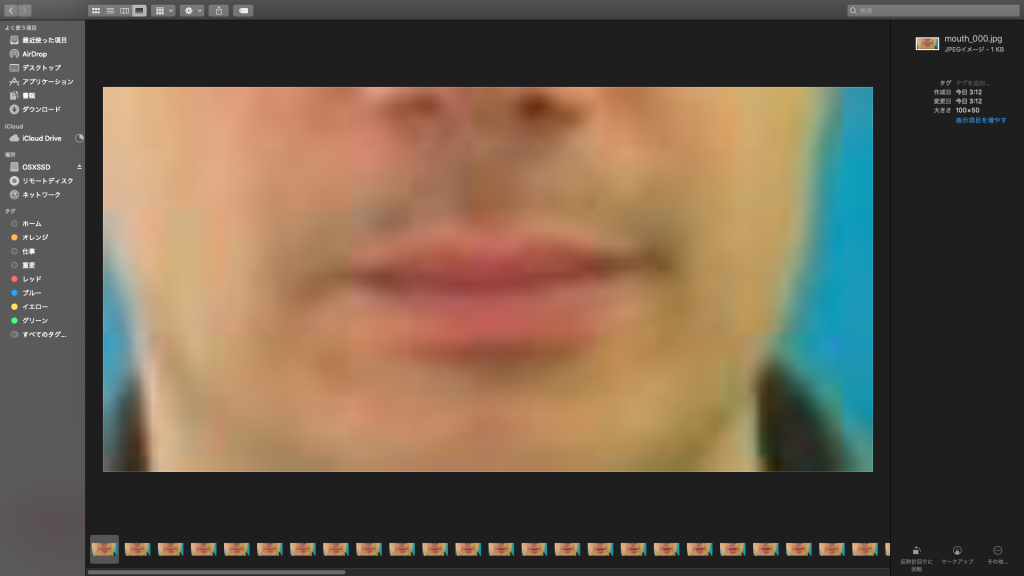
↑mpgを70枚のjpgにした
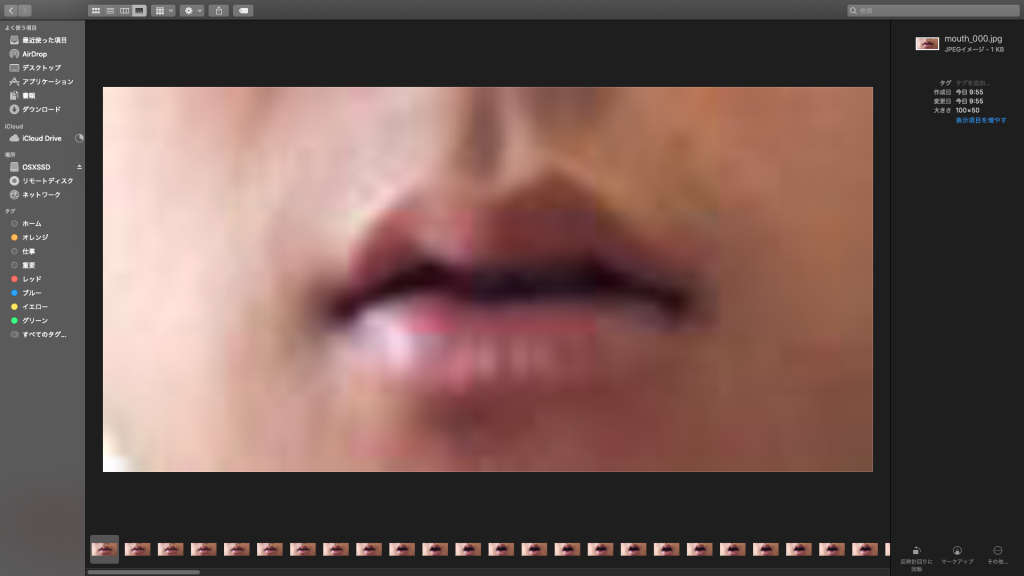
↑自分で撮った動画でもやってみた
・来週の目標:画質が荒くても良いのかまだわからないので、プログラムを動かして検証してみる
前回は認識できなかった撮影画像からのQRコードの読み取りができた。
画像が大きすぎると認識ができないようなのでリサイズし、二値化などの処理を施すことで読み取れた。しかし、認識精度があまり高くなく、かなり鮮明なQRでも読み取れず光の当たり具合や逆光などで全ての認識がうまくいくわけではなかった。
来週の予定:QRの認識精度が高いものがないか(Zbar)、画像によって補正の具合を調整できないか検討する。
黒点とサビの画像を全て60×60にリサイズした。
↓を参考にラベル付けをしようとしたがよく分からなかったので、今週できるようにする。
https://qiita.com/ufoo68/items/69b855b3b757c65ac139
ラベル付けしたらSVMで試す。
Stay Hungry, Stay Foolish!
