今週の進捗
- 冬季インターン用エントリーシート作成中(日立、パナソニック)
- 先行研究調査→webカメラだけで熱源を感知する研究はなかった。
今後の課題
- エントリーシート作成
- 基礎実験
- TOEICの勉強

財前:動く背景の除去を優先し、オプティカルフローやシフトなどのアルゴリズムからヒントを得てください。
五十君:fastTextの学習用データの構成仕方を確認し、一つのお店の商品名モデルを構成する。
水戸:目線マウスにするため、手を使うのがよろしくないので、顔ののパーツに機能をつける。ただし、目線を使うと目による情報収集に支障が出ますので、カーソルの動きは顔の向きでコントロールした方が良いと思われる。目の瞬きなどをクリックなどのアクションに割り当てる。
二石:偏光板の光に対する透過率と偏光率が定義されているので、これは人間の視認性と機械の可視性の折り合いがつくものに選べば、現存の交通標識適用可能との結論に持っていきたい。
白石:NPZファイルの構成が正しくない可能性があるので、動くサンプルをもう一度中身について解析し、エラーの原因を見つける。
北原:データの前処理が時間がかかり、処理待ち状態です。DL-BOXがCUDA9.0にアップデータしたので、使用可能かを確認すること。
ラベル付けしたデータセットを用意した。(黒点とさび)
それを読み込んで、train_test_splitでX_train,X_test,y_train,y_testに分けようとしているができてないので今週も続けていく。
テストサイズは0.3にする。
偏光板を用いたQRコードを反射板の上に製作、スキャンを行うことができた。
夜間を想定した画像では、二値化の段階でQRコードが崩れ、日中を想定した画像では二値化処理の段階では特に問題はないように見えたが読み込みできなかった。
リサイズの大きさが適度でなければ読み込みができないので改善方法を検討したい。



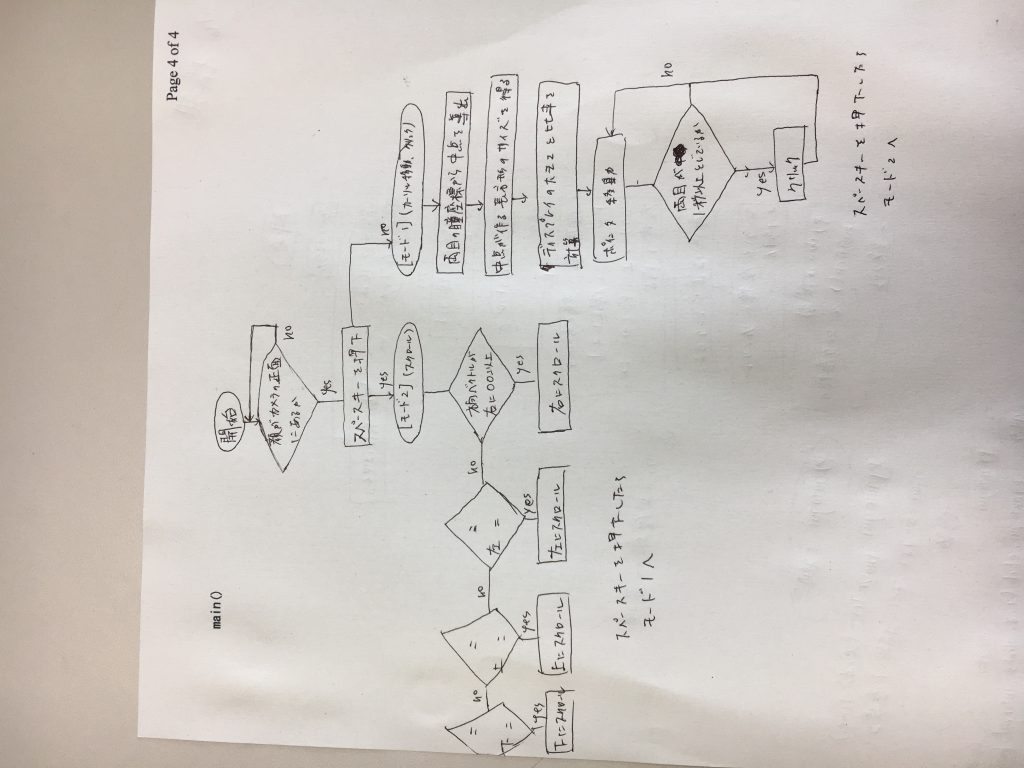
関数pyautogui.moveTo()により指定した座標までカーソルを持っていけることを確認した。次にシステム構成を考案した。先週は顔の方向ベクトルと黒目の位置により視点を定める方針にしていたが、もっと簡易的なシステムを作り上げたのち処理の複雑化をしたほうが効率的だと考えた。カーソル移動とスクロールでモード分けする予定です。
簡易的なシステムの条件を以下とする。
・カメラの位置はディスプレイの中心
・被験者はカメラの正面に立つ。ディスプレイ表示で正面に来るよう指示
・モード変更はスペースキーで行う
[カーソル移動、クリック]
・顔の向きはカメラと正対
・左右の黒目の座標を結んだ線分の中点を基準点とし、画面の左右上下端を見た時の座標で長方形ができるはずなのでディスプレイの大きさとの比率でカーソルの移動量を定める
・クリック動作は両目を1秒以上閉じたときとする。動作時にクリック音をスピーカー出力する。
[スクロール]
・顔の方向ベクトルの計算によりある値より大きくなるとその方向にスクロール
・目線情報はスクロールの際の材料にしない。
※カーソル移動について、斜視の人でない限り左右の瞳は同じ動きをするのでどちらか一方の瞳を用いてカーソルの移動量を計算する方法も検討する。
※中点の出し方
{(右の瞳の座標)+(左の瞳の座標)} / 2.0
テーマ「文字認識を用いた買い忘れ防止案」
今週の進捗
・fastTextの学習済みモデルによる類語抽出を試してみたが、食品以外にもたくさんの言葉が学習されているため、1単語に対しての類語抽出に約1分30秒ほどかかり、類語も食品とは関係ないものばかり抽出されました。
研究相談
①
http://tech.wonderpla.net/entry/2017/10/10/110000
https://qiita.com/kaka__non/items/0c5efaaa61cc1c4a553b
以上のサイトを参考にして、例えばお米の品種について学習させようとして学習データを作るとすると、(_label_1 = お米)
「_label_1,コシヒカリ ひのひかり あきたこまち ・・・」
「_label_1,あきたこまち ひのひかり コシヒカリ ・・・」
「_label_1,ひのひかり コシヒカリ あきたこまち ・・・」
とこんな感じで、品種名を入れ替えたテキストをいくつも用意すればいいのかと考えましたが、これは学習データとして適しているのでしょうか?
1、flickrを使い、いちご、トマト、りんごの画像をそれぞれ500枚ずつ集めた。
2、VGG16転移学習のプログラムから3つの画像の判別を行なった
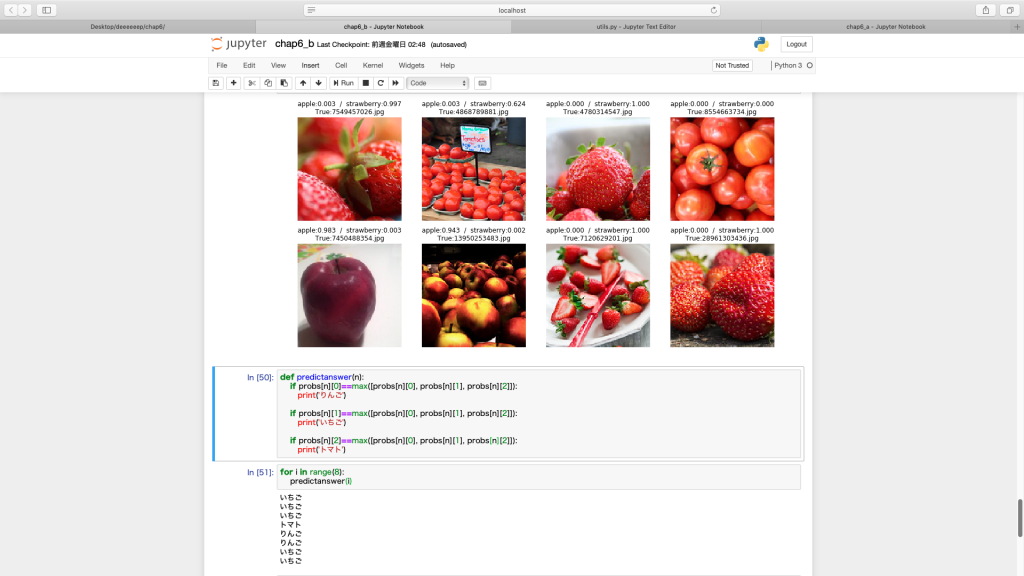
結果は8個中7個正解
元のプログラムを書き換えて作ったがまだ十分に理解できておらず、判別する画像をランダムで8個選んでしまう
3、google collaboratoryでGPUを使うために写真とラベルをpickleファイルに変換した
google collaboratoryにおいてpickleファイルを解凍した写真を上記(2)のプログラムで使用する方法がわからない
庄司さんゼミで学んだことでプログラム作成中
4、商品棚から商品をとる動画を撮影した。(2)で判別できた画像を元にトリミングの仕方サイズなどをもっと考える
テーマ:機械学習を用いた読唇精度の向上
githubにあるLipNetのコードを動かそうとした.
https://github.com/rizkiarm/LipNet:知識不足で実装できず
https://github.com/sailordiary/LipNet-PyTorch:Macでは動いたが1epochが17日となったため、DL-BOXで動かそうとしたがCUDA8がPytorch1以上に対応しておらず断念。
https://github.com/osalinasv/lipnet:tensorflow1.1なのでDL-BOXでも動かせそう。前処理に48時間くらいかかりそうなので待ってます。(11/11の深夜に始めた)
(追記)CUDA9になってました
今週の進捗