・日本語のOCR部分の基礎が作成できました。
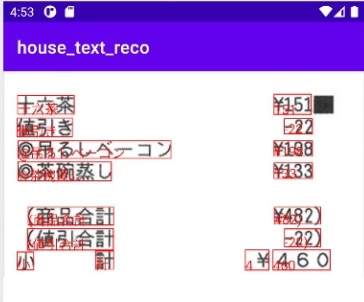
試しにネットで拾ったレシートをOCRにかけてみました。かなり拡大しているので見づらいですが、日本語の部分は全て正しく認識できていました。
・先週、画面構成を考えるように言われましたので、画面構成について書いた「画面遷移.pptx」をgitに置きました。

・日本語のOCR部分の基礎が作成できました。
試しにネットで拾ったレシートをOCRにかけてみました。かなり拡大しているので見づらいですが、日本語の部分は全て正しく認識できていました。
・先週、画面構成を考えるように言われましたので、画面構成について書いた「画面遷移.pptx」をgitに置きました。
インターネットから画像をスクレイピングして嗜好分類器を作成した。
画像を「アクティビティ」「風景」「建物」「食事」「その他」の5種類に分類するモデルをVGG16転移学習を行って作成した。
検証データでは88%の精度が確認できて嗜好性を判断するには十分なモデルだろう。
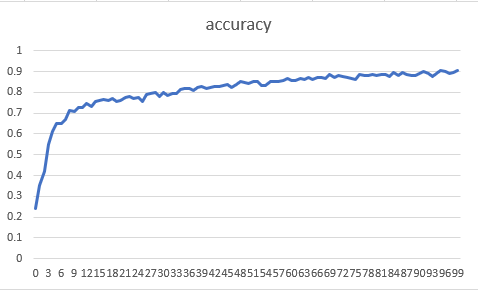

地名ごと、ユーザーごとに上記の分類モデルをロードして分類を行う予定。
Input: ユーザー名、地名
↓
processing: ユーザーの嗜好を分類モデルで判断
↓
output: 地名の画像データからユーザーの嗜好性が高い画像の一覧を表示させる
プログラムを組む予定。余力があればdjangoでwebアプリ作成。