Reading book: Grokking Deep Learning.

Keep processing experiment on BEVFormer.
GrokkingDeepLearning.pdf [English Version]
GrokkingDeepLearning.pdf [Chinese Version]

Reading book: Grokking Deep Learning.
Keep processing experiment on BEVFormer.
GrokkingDeepLearning.pdf [English Version]
GrokkingDeepLearning.pdf [Chinese Version]
Ran BEVFusion with TensorRT + ROS2 successfully.
But the result has some differences with the original compiled code. The first image is my result. It only detected two objects, while the official code could detect more objects.

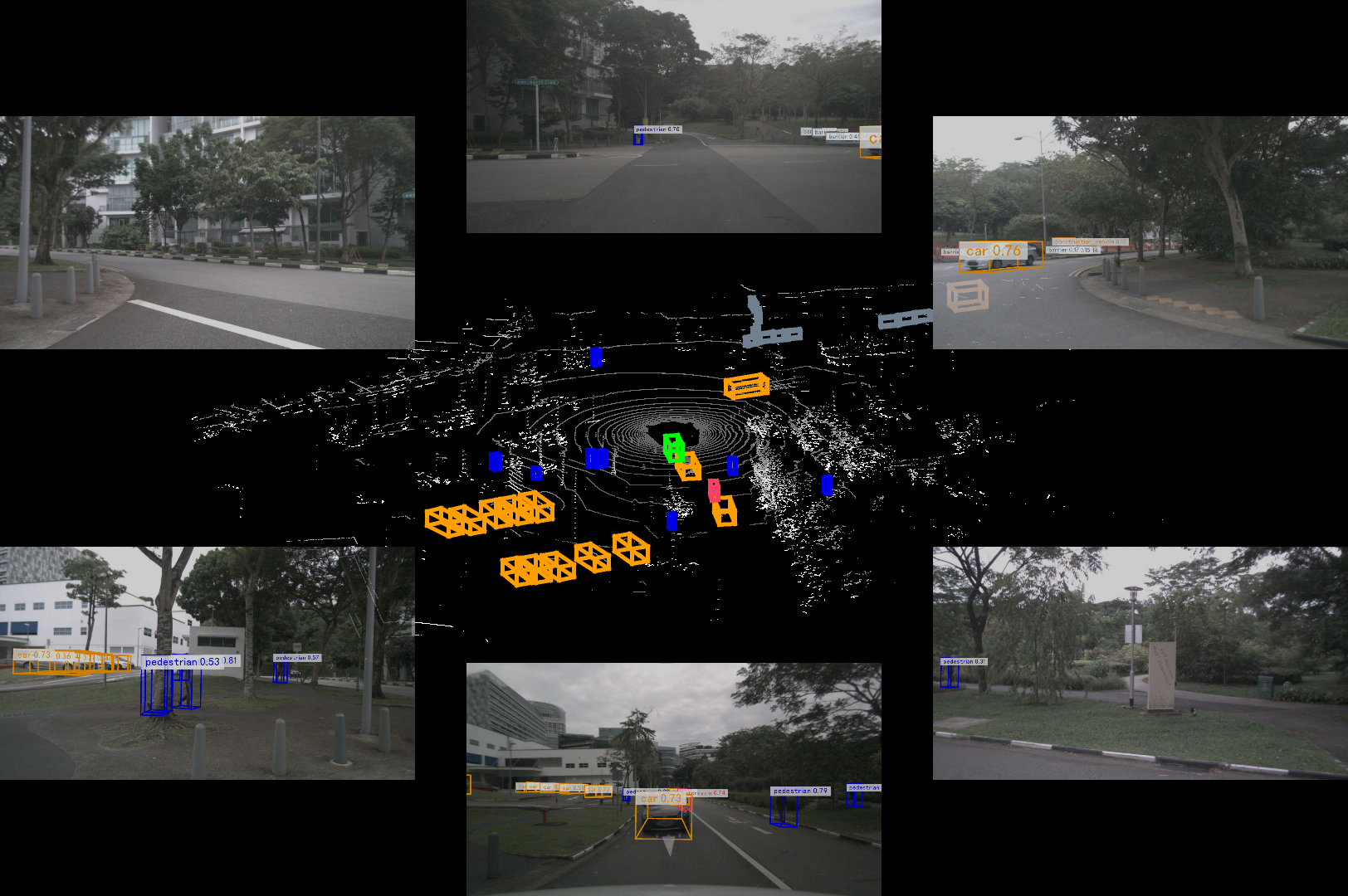
I will keep on finding solution.
BEVFormer:Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
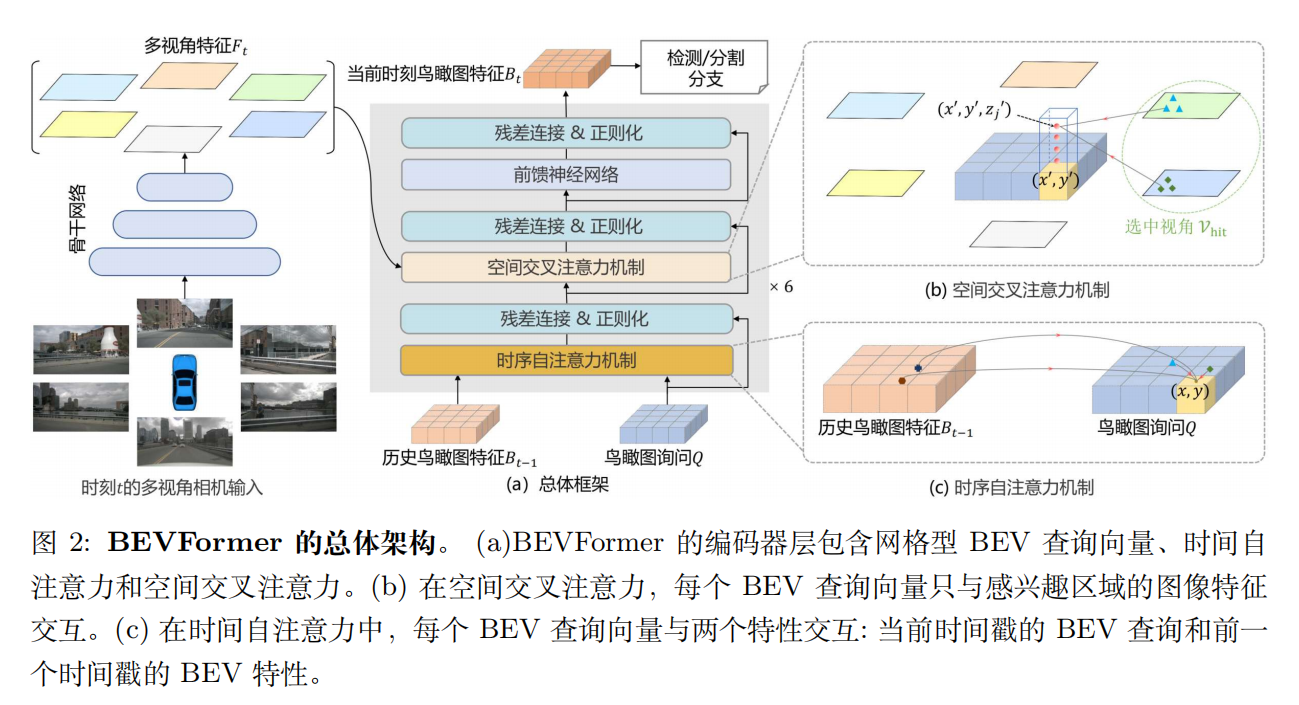
Learning the BEVFormer algorithm which based on VPN and LSS.
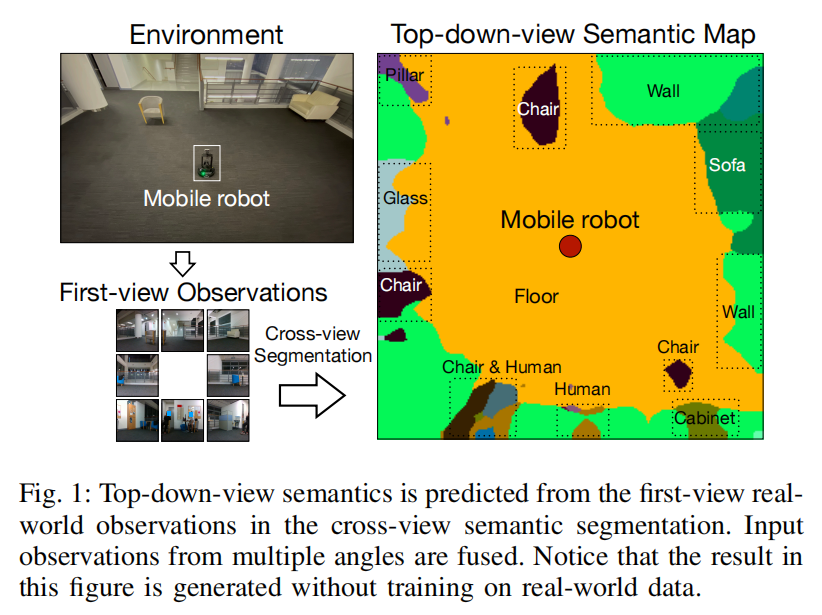
Cross-view Semantic Segmentation for Sensing Surroundings
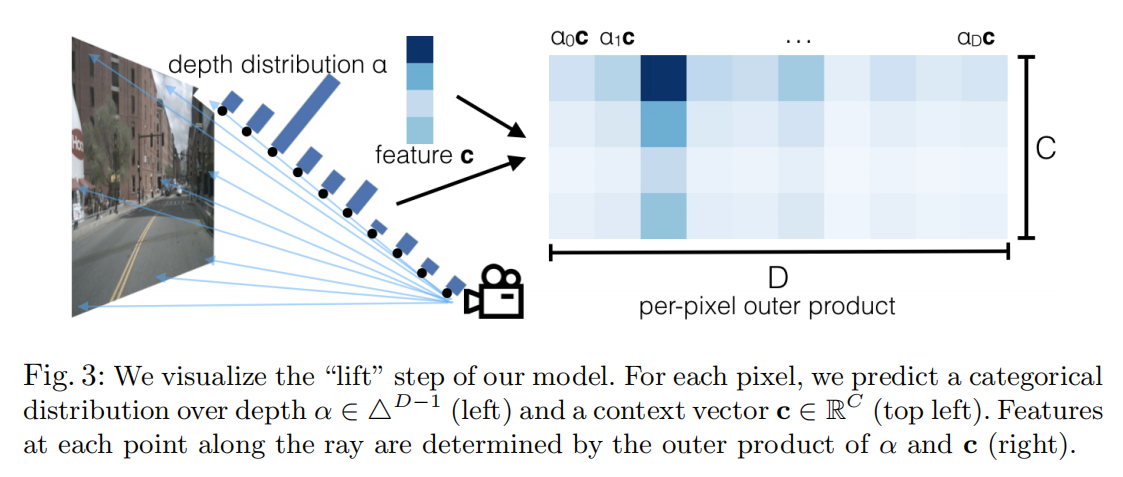
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
The output multi-scale features from FPN with sizes of 1/16, 1/32, 1/64 and the dimension of C = 256 . For experiments on nuScenes, the default size of BEV queries is 200×200, the perception ranges are [−51.2m, 51.2m] for the X and Y axis and the size of resolution s of BEV’s grid is 0.512m.
Experimenting on the platform of mmdetection3D:
Current work: use MVXNet and kitti to train a detector.
Kolmogorov–Arnold Networks
MLP (Multi-Layer Perception) is essentially a linear model wrapped with a layer of nonlinear activation functions to realize nonlinear spatial transformations. The advantage of a linear model is its simplicity, as each edge is two parameters w and b, which together are represented as a vector matrix, W. As the number of layers increases, the representation capability of the model increases.
C=6ND.
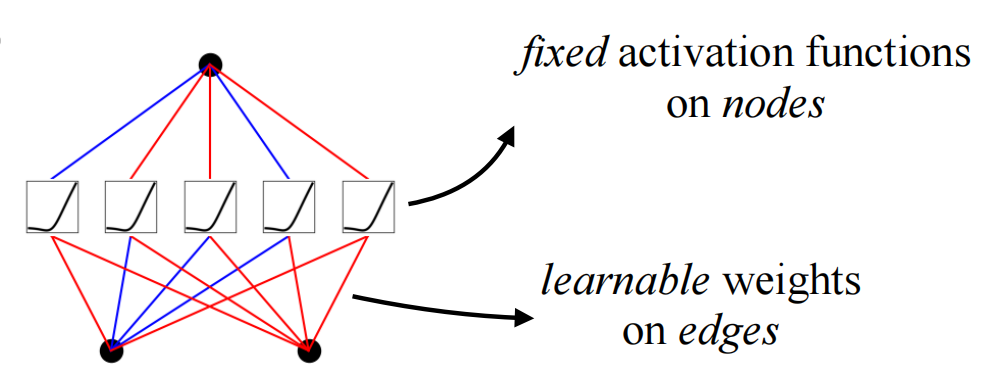
Comparing MLPs and KANs, the biggest difference is the change from fixed nonlinear activation + linear parameter learning to direct learning of parameterized nonlinear activation functions. Because of the complexity of the parameters themselves, it is clear that individual spline functions are harder to learn than linear functions, but KANS typically only require a smaller network size to achieve the same effect.
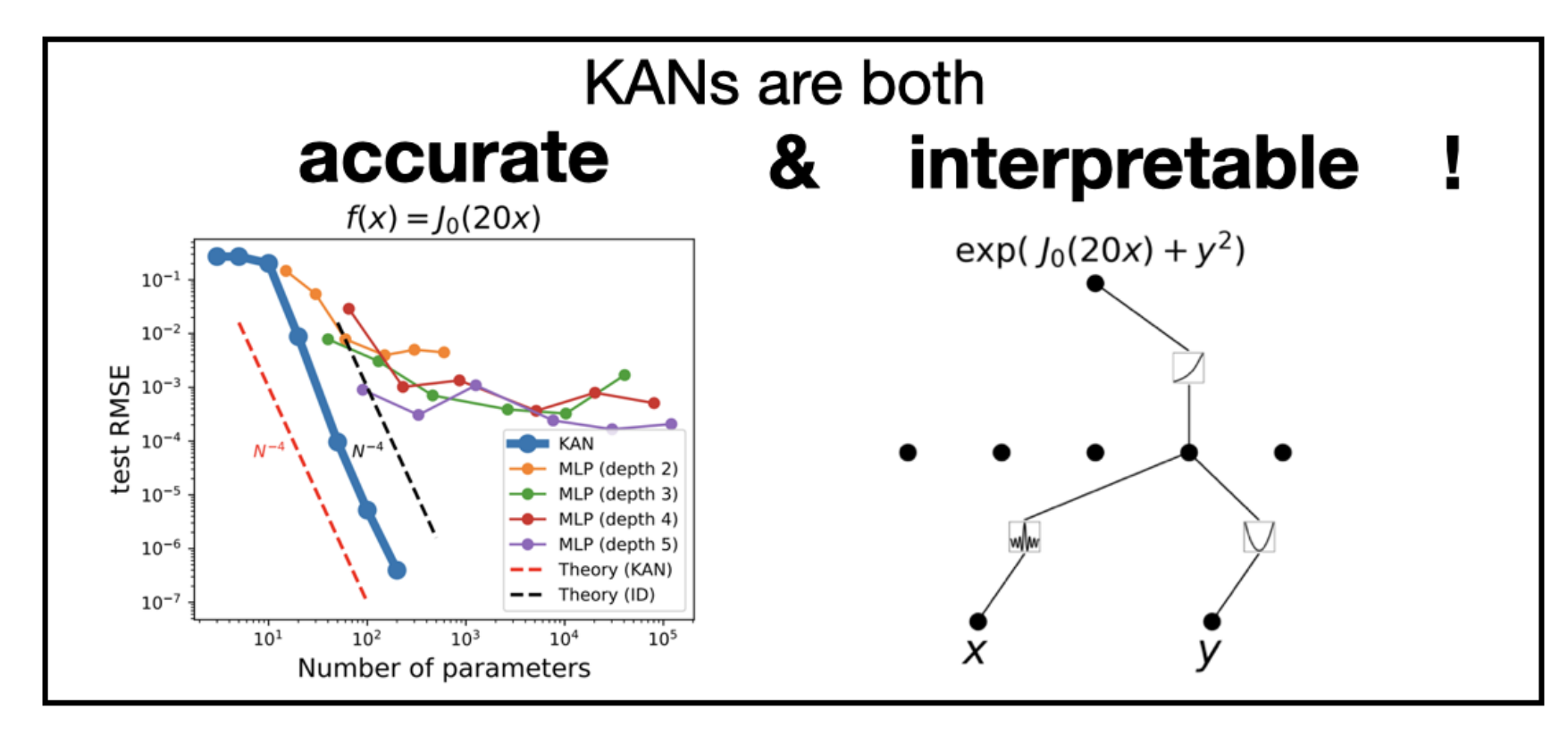
The paper shows us that even very few network nodes can achieve the same or even better results.

Fewer network nodes simplify the structure of the network, and thus the paper lends this to emphasize the interpretability of KAN networks.
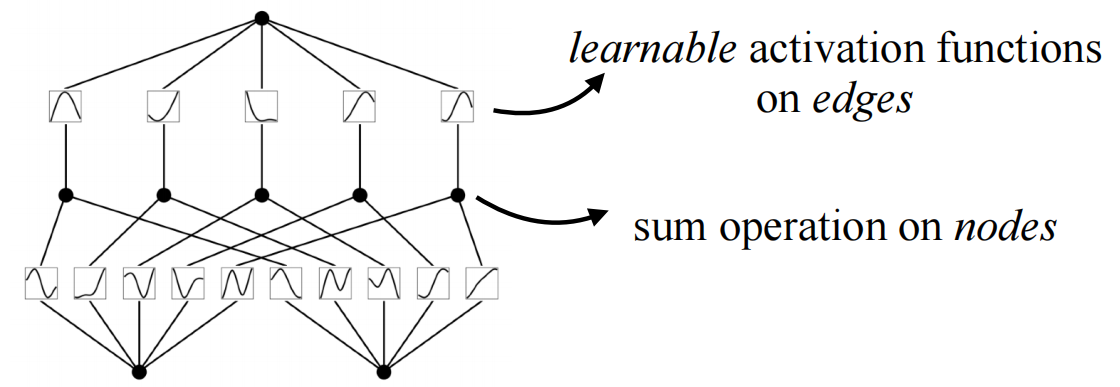
KAN structure
Many three-quarter period sine functions can be combined to fit functions of arbitrary shape. In other words, two summations with B-spline, an activation function, are enough.
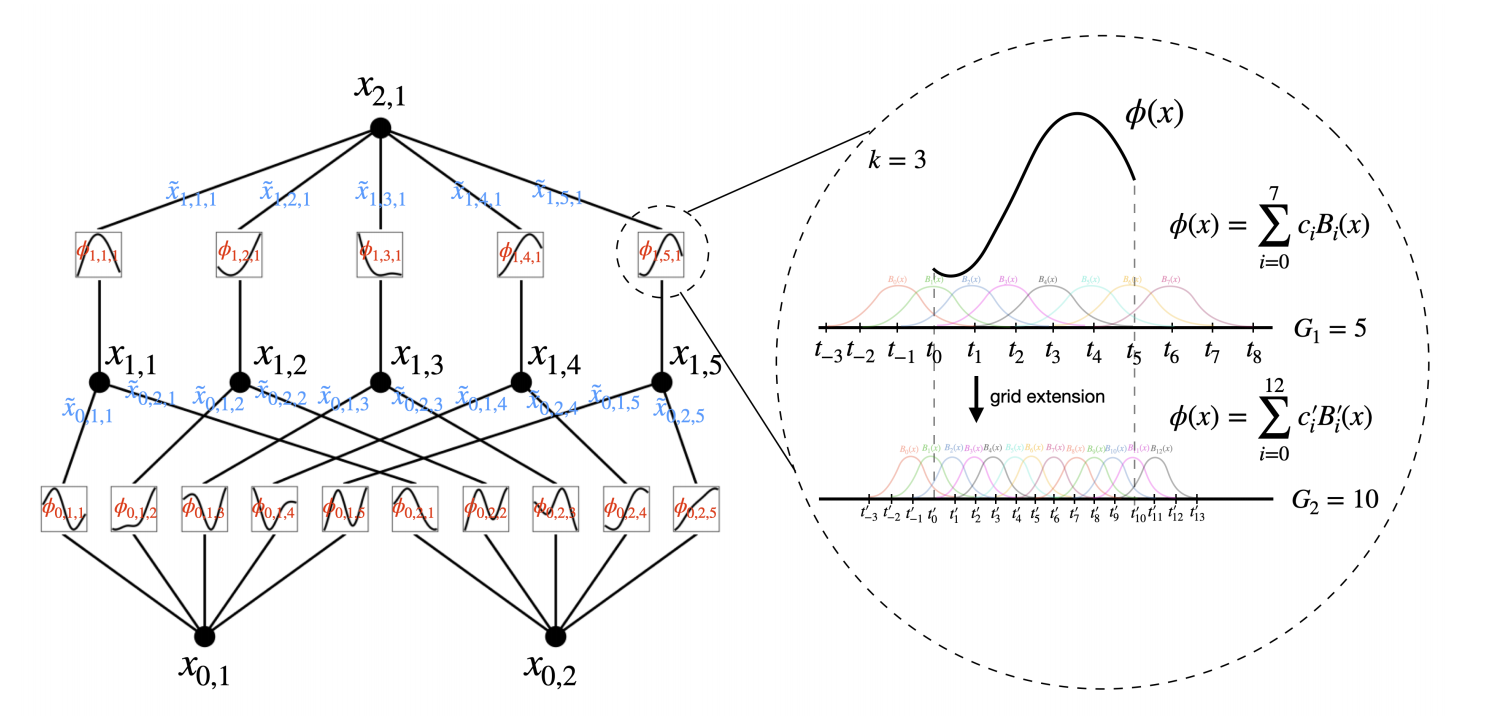
The number of layers and nodes of the KAN network are controllable and can be chosen arbitrarily:

Residual activation functions:
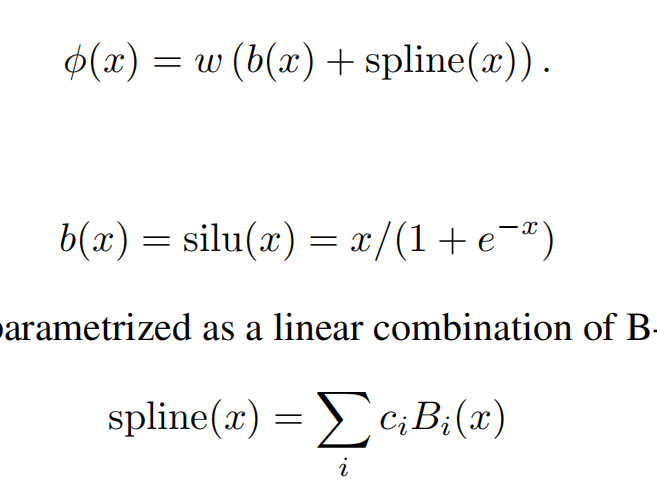
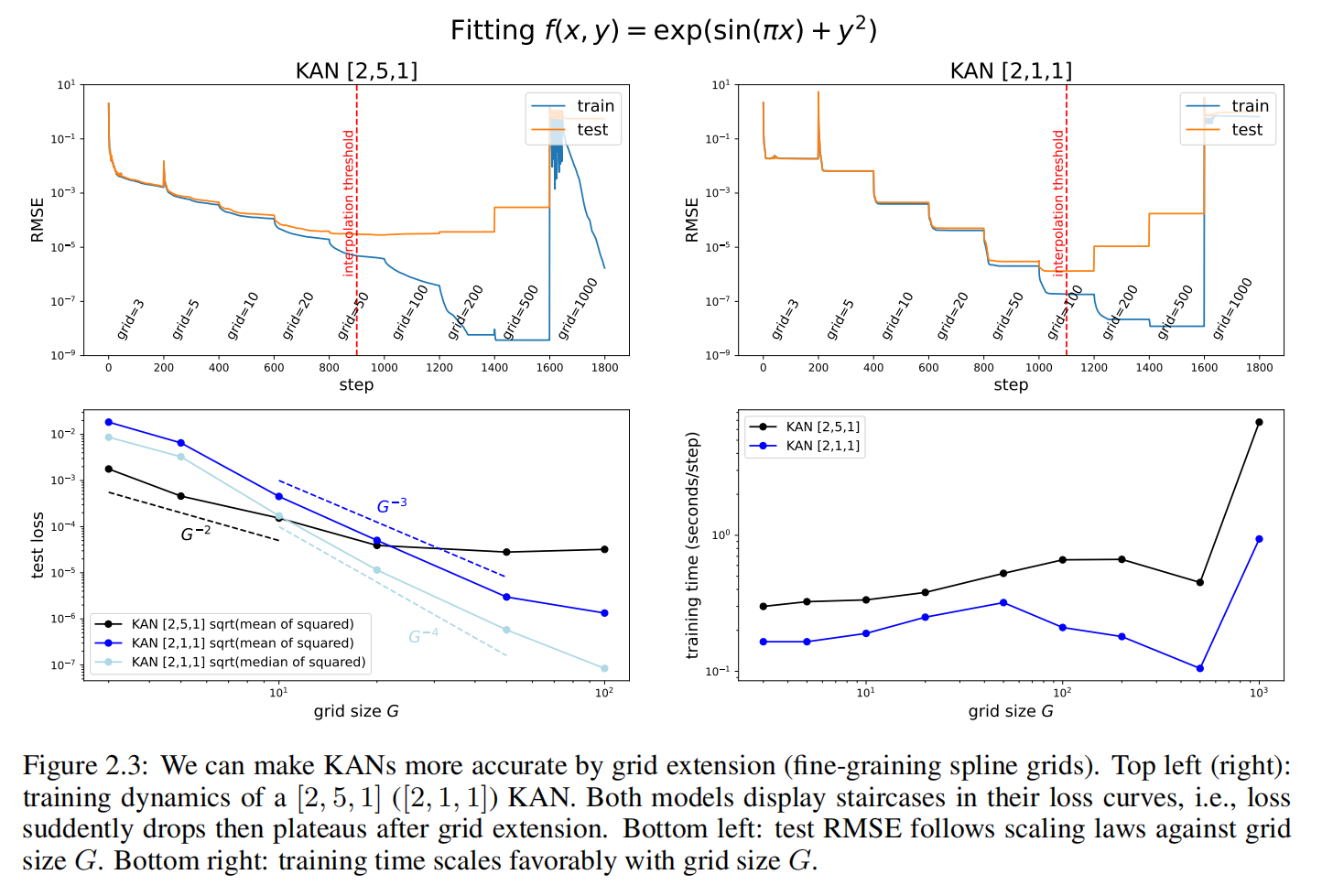
KAN accuracies
For KANs, one can first train a KAN with fewer parameters and then extend it to a KAN with more parameters by simply making its spline grids finer (???), without the need to retraining the larger model from scratch.
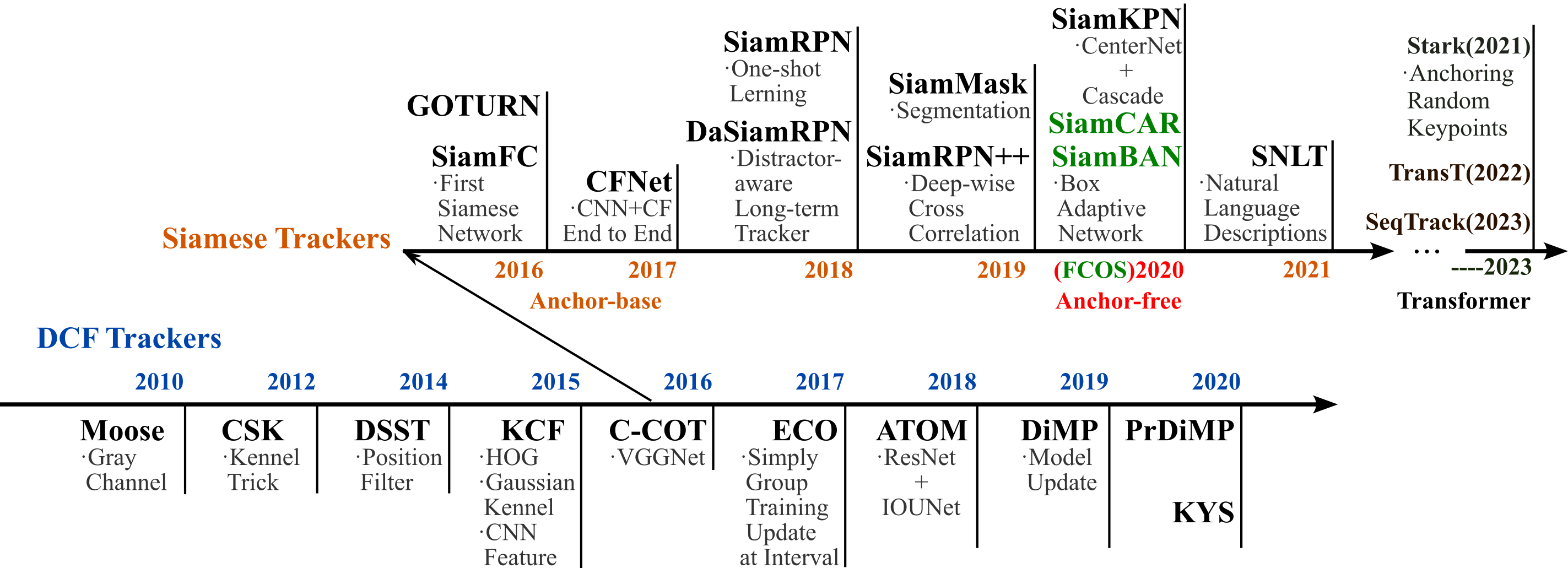
The work summary for the last week and this week is as follows: Reviewed the progress and main contributions of single object tracking algorithms over the years (2010~2023), summarizing the respective advantages of several representative algorithms. In conjunction with single object tracking, I explored the development history of 2D to 3D detection and tracking.
I learned how to use Inkscape to draw image with format of .svg and output results without distortion.
The main contribution of CenterPoint lies in its adoption of a center-based detection head, which simplifies the process of dealing with object positions by not considering their intrinsic orientations. This significantly reduces the search space of the object detector, especially beneficial when vehicles drive on straight roads. Traditional anchor-based methods struggle to fit axis-aligned bounding boxes to rotated objects during critical maneuvers like a left turn.
CenterPoint proposes representing, detecting, and tracking 3D objects as points. By regressing to 3D bounding boxes directly at the center point without voting, this method uses a single positive cell for each object alongside a keypoint estimation loss. A two-stage 3D detector with a Lidar-based backbone network identifies the centers of objects and their attributes, with a second stage refining all estimates.
3D object detection aims to predict three-dimensional rotated bounding boxes. CenterPoint directly regresses to 3D bounding boxes through features at the center point without voting. This method employs a single positive cell for each object and utilizes a keypoint estimation loss. The two-stage detector extracts sparse features of 5 surface center points from the intermediate feature map.
Initially, six tasks are generated in the code, with the nuScenes dataset comprising 10 categories. Four tasks have two categories each. The separation of regression for ‘car’ and ‘pedestrian’ is due to the relatively large difference in size, allowing both to achieve higher accuracy more easily. Grouping ‘pedestrian’ and ‘traffic cone’ in the same task is because their sizes from a Bird’s Eye View (BEV) are similar, which can avoid generating two different categories of targets at the same position. Every task has the same head, and each head has a similar structure, including predictions for offset, height, dimensions, rotation angle, velocity, and a heatmap center.
Many 2D tracking algorithms can directly track 3D objects out of the box. However, dedicated 3D trackers based on 3D Kalman filters still have an advantage as they better exploit the three-dimensional motion in a scene.
Solved the problems that the Spconv cannot be compiled:

Training the total dataset(nuScenes, 442.8GB) on RTX3090Ti cost me about 4 days.
![]()
Achieved the test results:
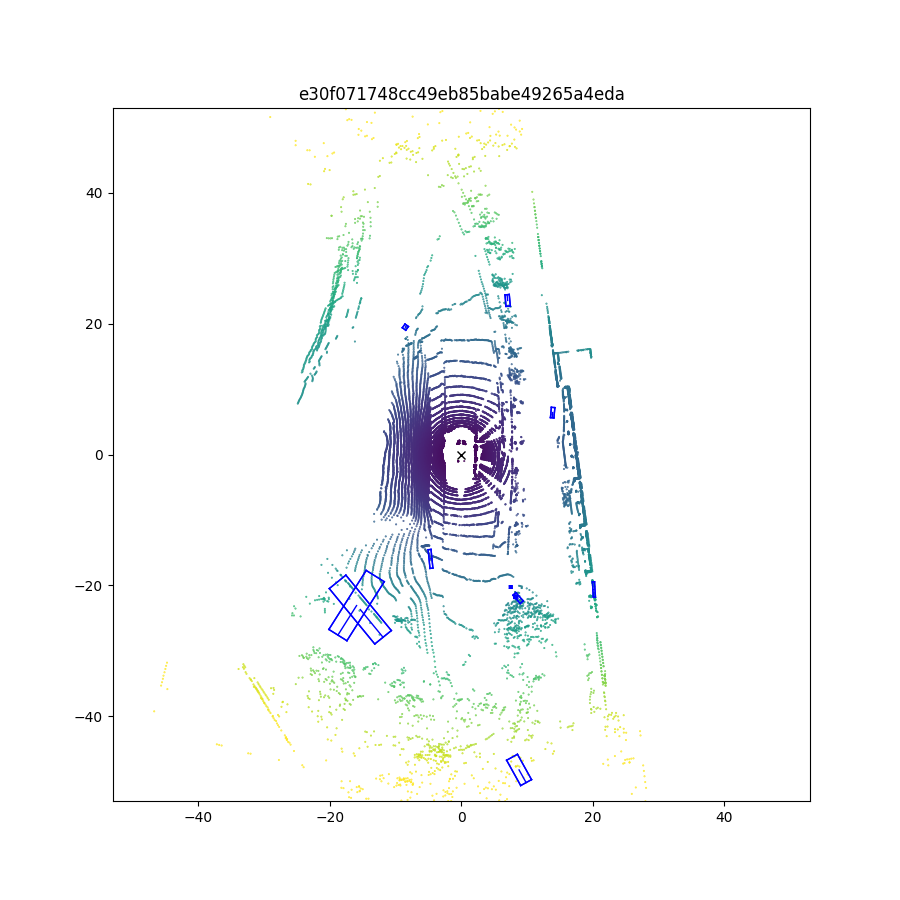

The result trained on my computer is almost similiar to the official result. Next, I will look for some advanced methods to modify the CenterPoint.
Recently, I was learning mmdetection3D.
It took me about 6 days to establish the complete conda envoriment and run the Python algorithm of CenterPoint in my system (Ubuntu 20.04.6).
There is still a problem that the DCN part can be compiled, but it won’t run normally with my torch (1.12.0), an older version should be applied, but it will cause some other problems.
The CenterPoint contains two third-part libs, git clone cannot download both of them. They should be cloned desperately. And then, re-adding the CUDA path, CenterPoint path and third-part lib path to .bashrc. Definitely, one of libs can be installed by pip without compiling…… After that, this problem was solved.
2. RuntimeError:
———————————–File“/home/omaqzy/PycharmProjects/CenterPoint/det3d/ops/dcn/deform_conv.py”, line 93, in backward cur_im2col_step)
RuntimeError: view size is not compatible with input tensor’s size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(…) instead.
————————————–
This is the problem about DCN. Replaced the AT_CHECK with TORCH_CHECK in file deform_conv_cuda.cpp and deform_pool_cuda.cpp, so that the DCN can be compiled. When I run it to train the model, I will face the above problem.
The train result:
Solve the above problem.
Learn the 3D-Detection and try to modify the algorithm.
Review the Kernel-based, Subspace-based and Sparse Representation tracking methods.
Read some papers and found that some improvement points are based on Kalman Filter.
Prepare the PPT for next week.