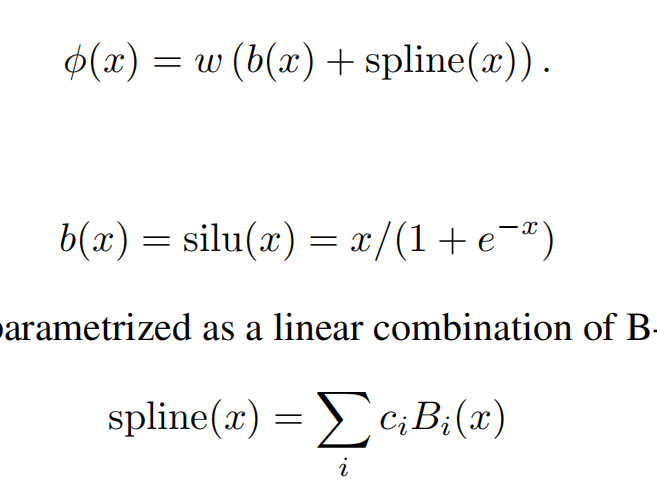Kolmogorov–Arnold Networks
MLP (Multi-Layer Perception) is essentially a linear model wrapped with a layer of nonlinear activation functions to realize nonlinear spatial transformations. The advantage of a linear model is its simplicity, as each edge is two parameters w and b, which together are represented as a vector matrix, W. As the number of layers increases, the representation capability of the model increases.
C=6ND.
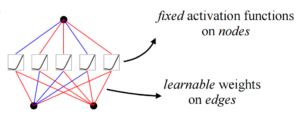
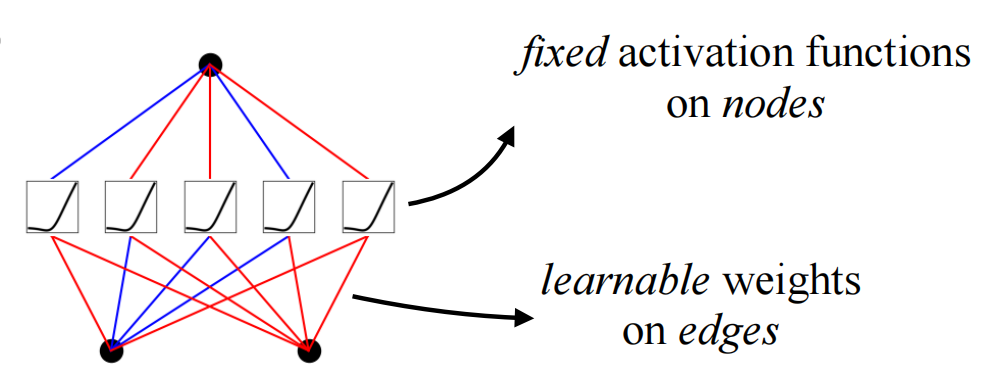
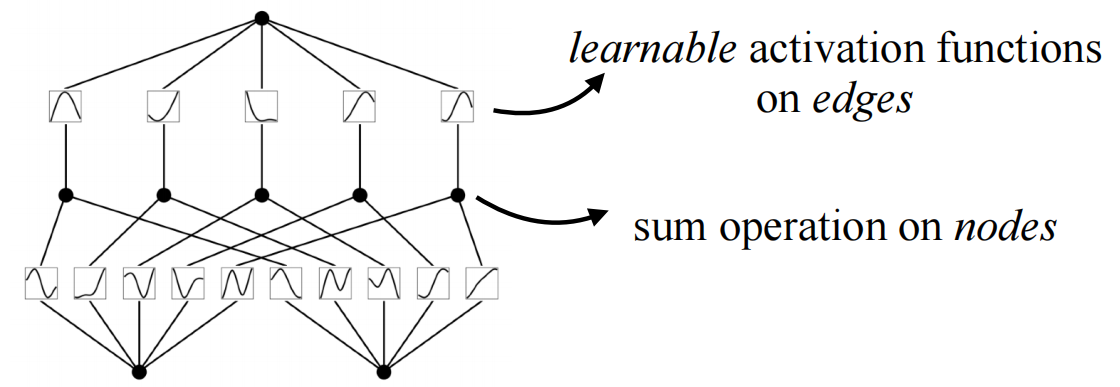
Comparing MLPs and KANs, the biggest difference is the change from fixed nonlinear activation + linear parameter learning to direct learning of parameterized nonlinear activation functions. Because of the complexity of the parameters themselves, it is clear that individual spline functions are harder to learn than linear functions, but KANS typically only require a smaller network size to achieve the same effect.
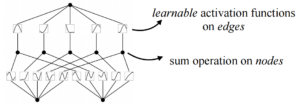
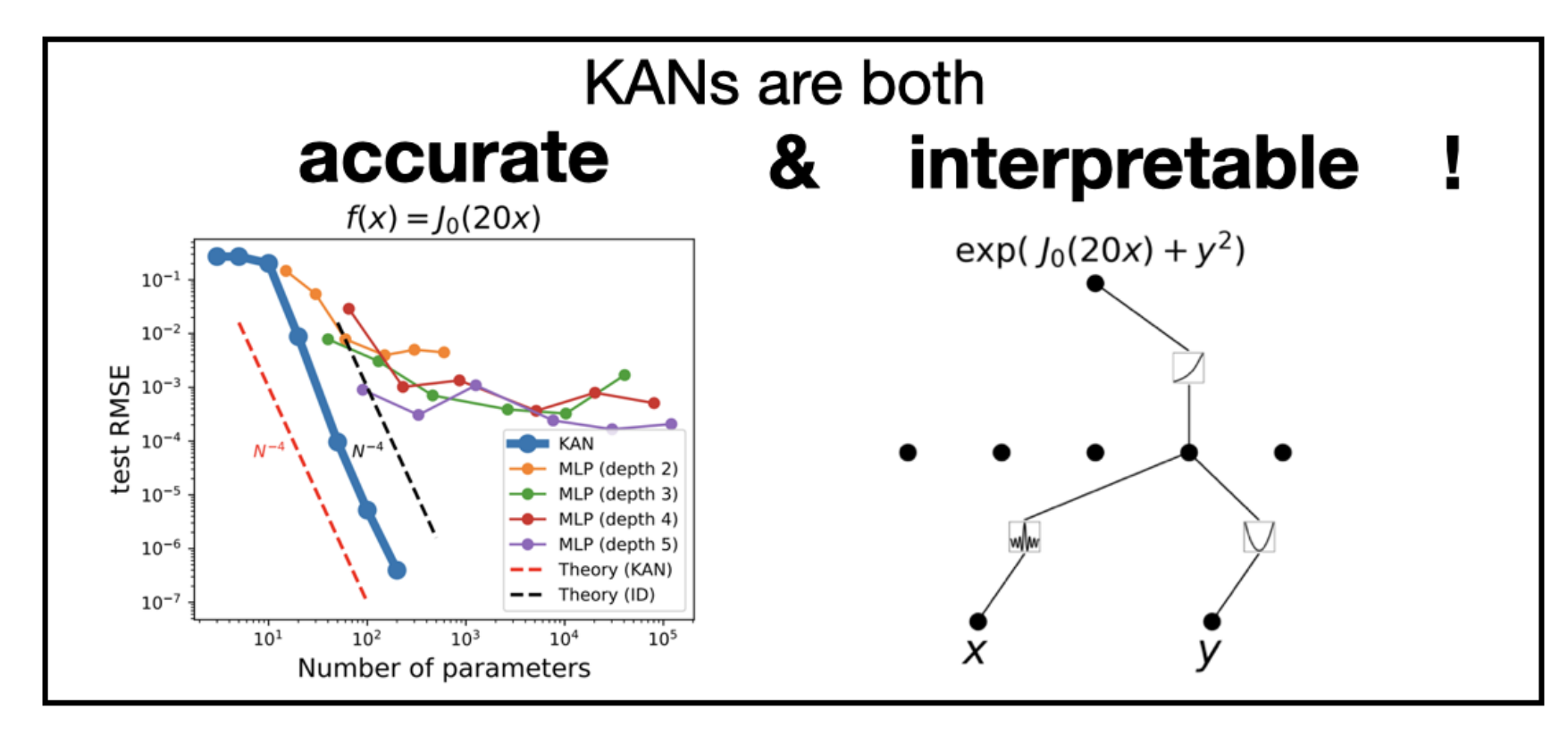
The paper shows us that even very few network nodes can achieve the same or even better results.

Fewer network nodes simplify the structure of the network, and thus the paper lends this to emphasize the interpretability of KAN networks.
KAN structure
Many three-quarter period sine functions can be combined to fit functions of arbitrary shape. In other words, two summations with B-spline, an activation function, are enough.
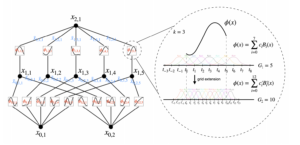
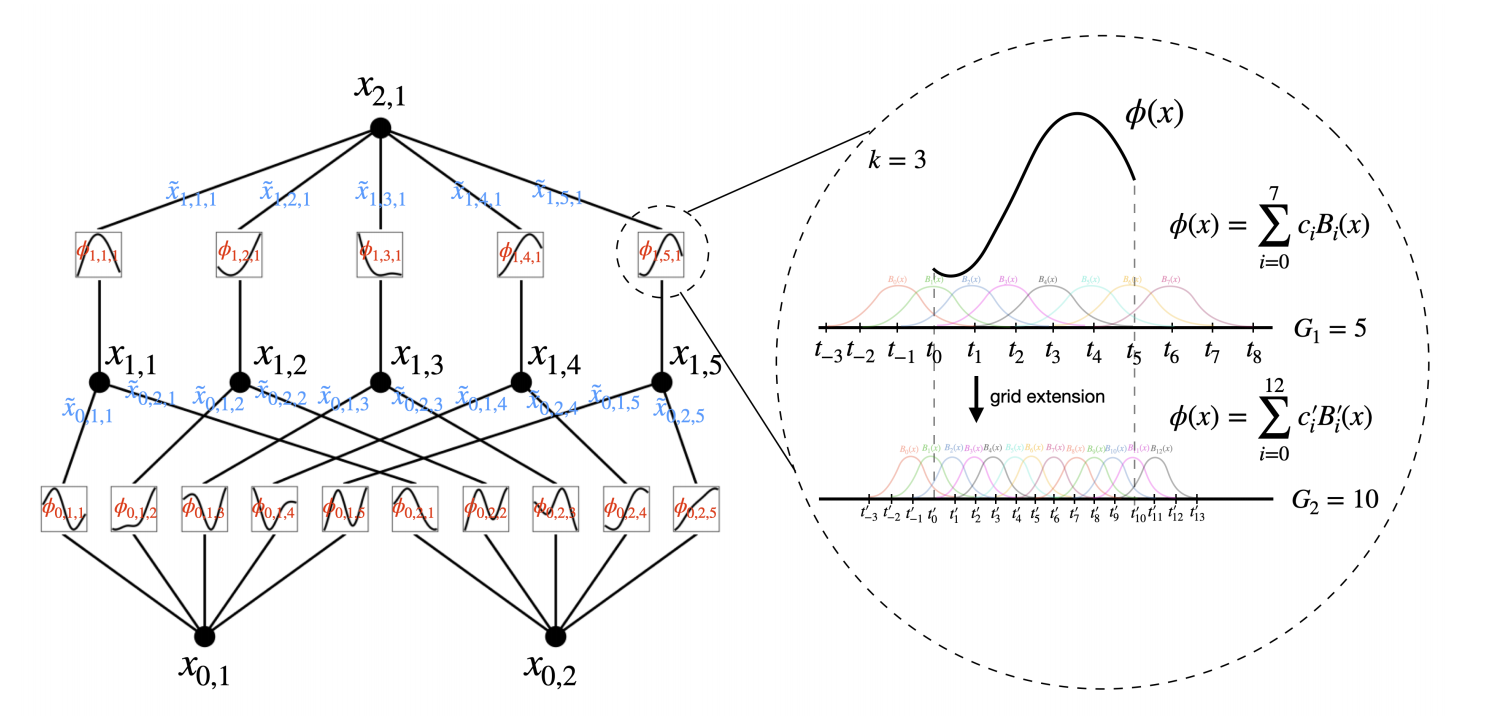
The number of layers and nodes of the KAN network are controllable and can be chosen arbitrarily:

Residual activation functions:
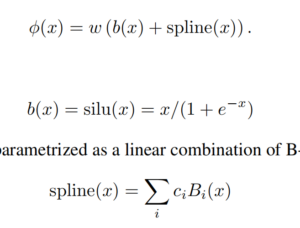
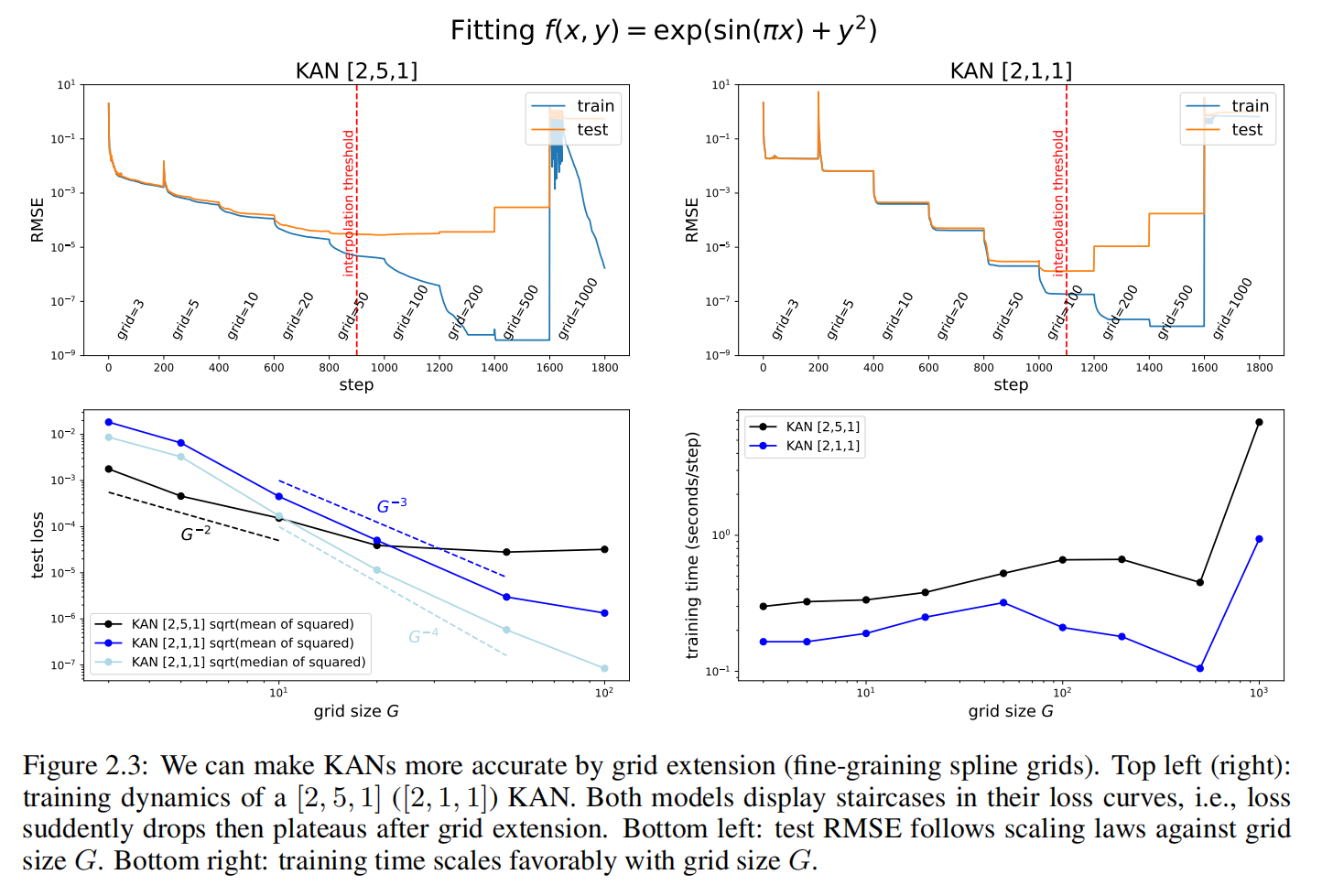
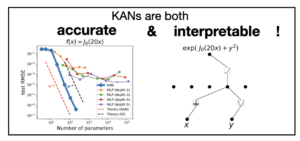
KAN accuracies
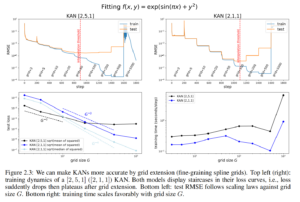
For KANs, one can first train a KAN with fewer parameters and then extend it to a KAN with more parameters by simply making its spline grids finer (???), without the need to retraining the larger model from scratch.
KindXiaoming/pykan: Kolmogorov Arnold Networks (github.com)