大ゼミでのご指摘
- データ収集の方法がわからない→アニメーションを用いる
- ラベルの0,1を説明
- 学習データが少ない方が良い理由→無駄なデータがないからと言い切る
- モデルの作り方には汎用性がある(実験1を違う被験者でもしないといけない)→被験者Aのモデルを被験者Bには用いることができないという意味で汎用性はないがそこは言わない
- 使っている5つの生体信号をなぜピックアップしたのかを文献を用いて説明する(原理の追加)
全体的にやったことを全部述べるのではなく、意味のあったことを述べていった方が良いか?
今後のこと
- 実験1の被験者を最低1人増やす
- 実験3についてはデータ増やさなくて良い
- 論文執筆
研究進捗
- 他人のデータを自分のモデルに突っ込んでみた(自分のデータに混ぜて標準化、別々で標準化2パターン)
→わかってはいたがうまく判定できなかった。
良モデル作成には、今のところ自分のデータを使うしかない(飲酒前後30分でできる)
- スマートウォッチを使って取得した自身のデータを使って飲酒状態を推定した
→少ないデータで学習し構築したモデルの方が精度が良かった。
学習データ少↓
学習データ多↓
本日他人のデータを撮ってモデルの評価をしたいと思います。
研究進捗
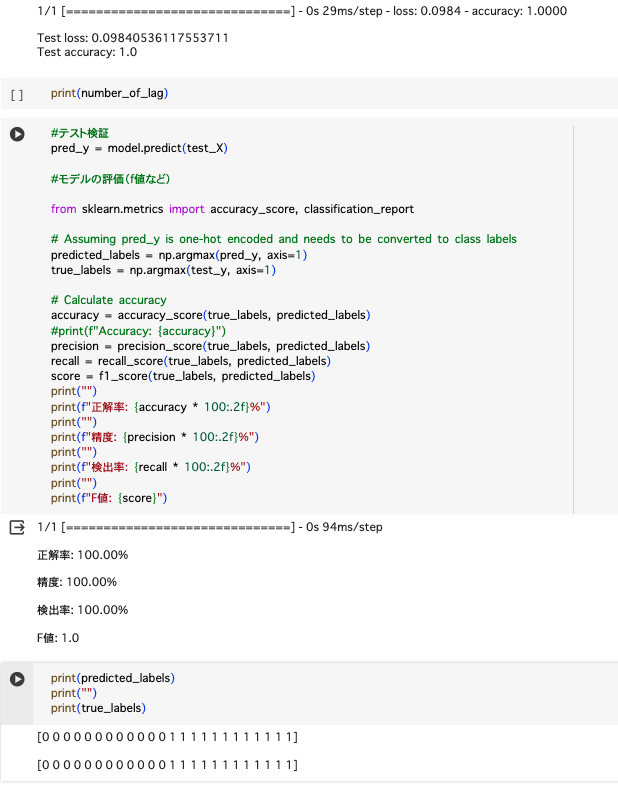
・別日に取ったデータを使いモデルの評価
→ロジスティック回帰
勉強
研究進捗
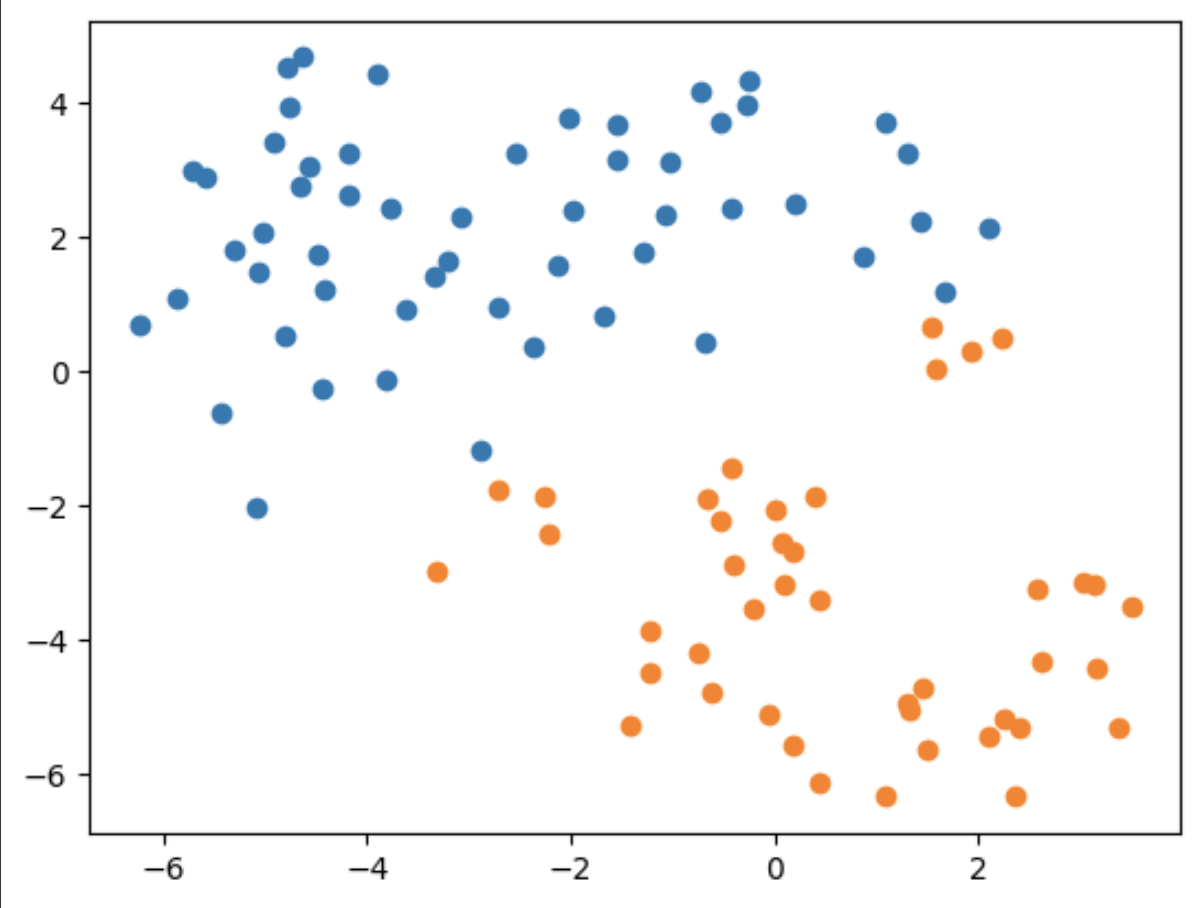
- クラスタリング→ラベルがわかっているため精度を出すと約66%
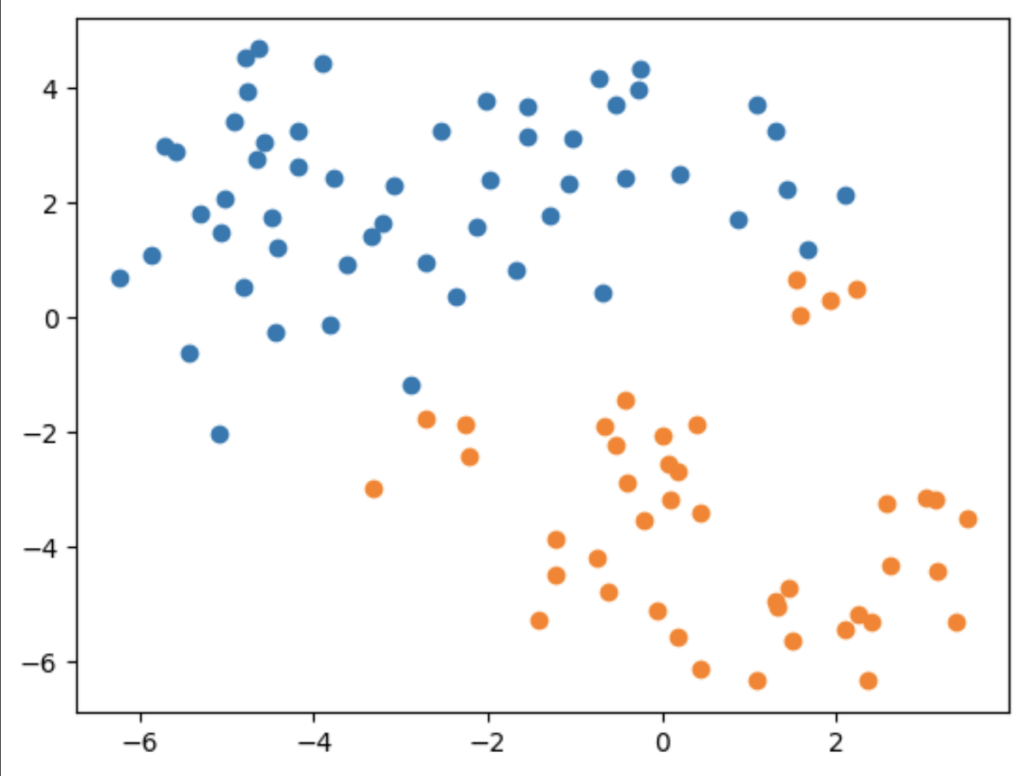
- クラスタリングを説明変数の組み合わせ全て試したが、どれも改善はしなかった
研究進捗
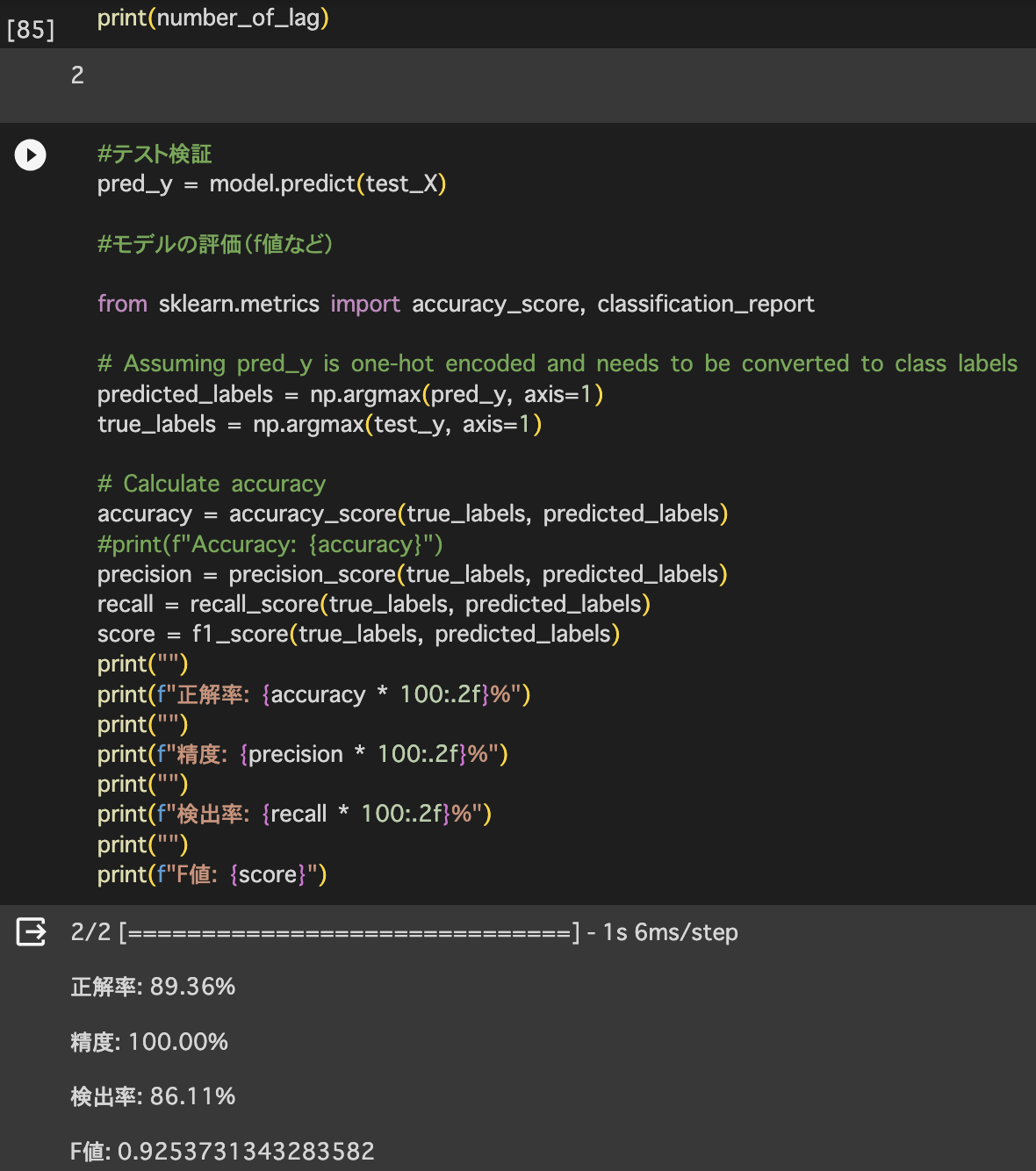
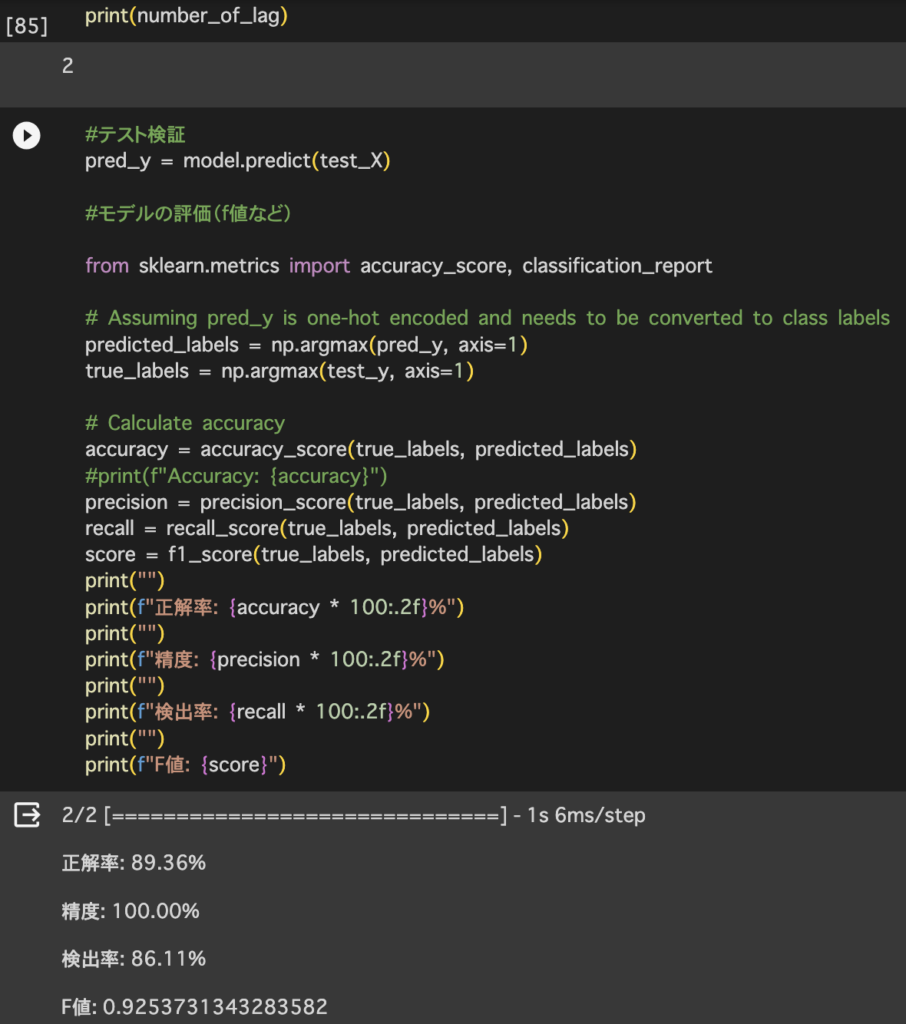
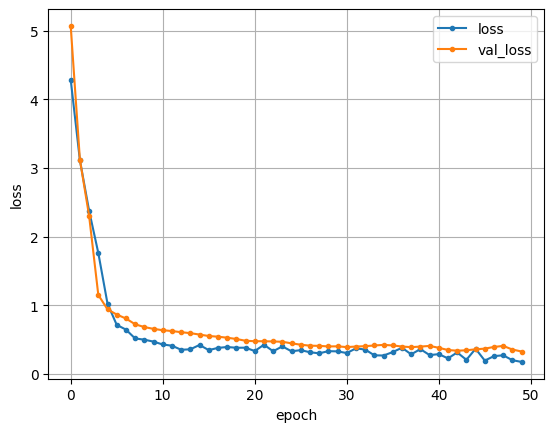
- LSTM_newモデル作成(未完),LSTMはchat GPT→タイムステップ(ラグ)2の時が一番精度良い

勉強
先生方からのご指摘
- 実際の血中アルコール濃度を検出しているわけではないので、検出→推定に変える。
- アルコールインターロックシステムに使える推定方法なので、アルコールインターロックシステムの名前を絡ませる。もしくは、アルコールチェッカーよりも優位な点を示す。
- 生体パラメータは飲酒以外でも変化するので、飲酒状態を推定しているとは言い切れないのでは?→精度の高さで言い切る必要あり。
- 個人のためだけのモデルであれば、システムの補完に使えないのでは?→汎用化した時の精度を示す必要ある。もしくは運転者は誰かわかるので運転中にデータ採取、学習を行える方法を提案する必要あり
機械学習を用いた生体信号分析による飲酒状態推定法の有効性検証
とかにしようと思う
スマートウォッチと鍵を一体化したシステム→教師なし学習で二値分類→人の手を一度加えラベル付け→二度目から飲酒推定可能
研究進捗
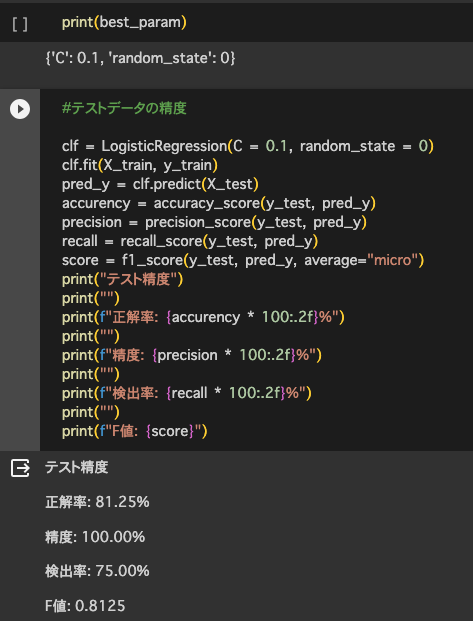
・グリッドサーチをしてハイパーパラメータの選定を行った
→ロジスティック回帰でモデル改善(C=0.1,random_state=0)
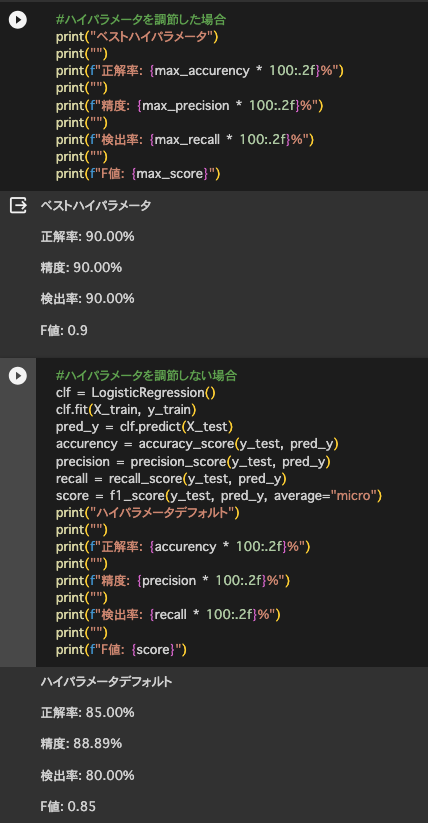
→SVMでもモデル改善(C=0.1,decision_shape=ovo,kernel=linear,random_state=0)
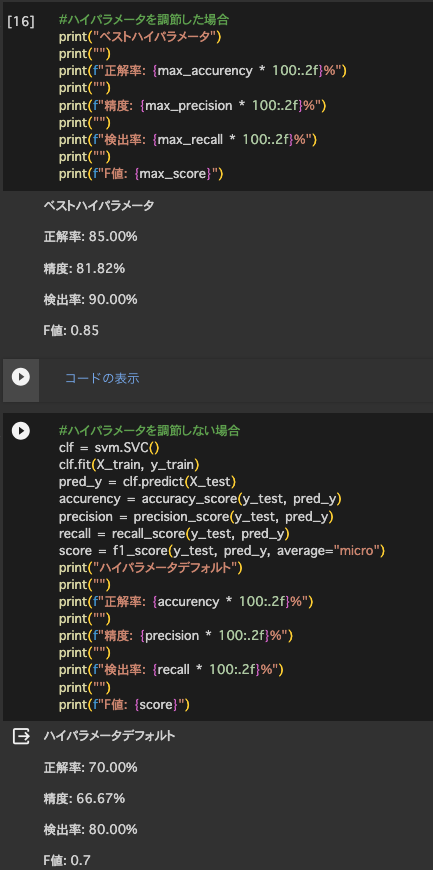
先週まではaccuracyだけで比べていた。
勉強
研究進捗
データ97個
・SVM
テストデータ20%、ランダムステイト42:テストデータ精度85%、訓練データ精度88.31%
・ロジスティック回帰
テストデータ20%、ランダムステイト42:テストデータ精度85%、訓練データ精度88.31%
訓練データ100%:訓練データ精度79.31%
検討事項・わかったこと
・SVMとロジスティック回帰で精度が全く同じなのはなぜなのか
・random_stateを変えると訓練データ精度が多少変わる
勉強
Stay Hungry, Stay Foolish!