(1) I am still training the model after exchanging the tracking datasets with the trajectory datasets.
(2) I am still making a GUI to compare multiple Super Mario RL agents.

(1) I am still training the model after exchanging the tracking datasets with the trajectory datasets.
(2) I am still making a GUI to compare multiple Super Mario RL agents.
(1) I am training the model after exchanging the tracking datasets with the trajectory datasets.
(3) I am still making a GUI to compare multiple Super Mario RL agents.
(1) I am training the model after exchanging the tracking datasets with the trajectory datasets.
(2) I am reading the paper about dense optical flow, trying to find a simple method to compute background motion.
Paper Link: https://arxiv.org/pdf/2305.12998v2
(3) I am still making a GUI to compare multiple Super Mario RL agents.
(1) To help the trackers identify similar objects, I am still modifying the tracking datasets as the trajectory datasets before training the model.
(2) Try to find a simple method to compute camera motion.
(3) I am making a GUI to compare multiple Super Mario.
(1) To help the trackers identify similar objects, I am still modifying the tracking datasets as the trajectory datasets before training the model.
(2) Try to find a simple method to compute camera motion.
(3) I am making a GUI to compare multiple Super Mario.
(1) I am still studying how to apply trajectory prediction to long-term object tracking.
(2) About the the display of achievements in August, I am finding some of my previous projects, involving object tracking, deep reinforcement learning, large language models, and optical character recognition.
This week, I continued to conduct experiments on trajectory prediction.
I conducted visualization research on the code for the paper “Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural
Network for Human Trajectory Prediction”.
The initial predicted trajectory is very normal.

But in the later stage, the predicted trajectory will lag behind the actual position of pedestrians.

And the predicted trajectory always appears in the middle of the image, which is also a problem.
I will find the reason to solve the problems.
(1)Recently, I have been reading papers on trajectory prediction, conducting experiments, and trying to understand the code.
Contine reading papers about long term tracking.
The paper try to modify the superdimp to a long-term tracker. It present a global search method and
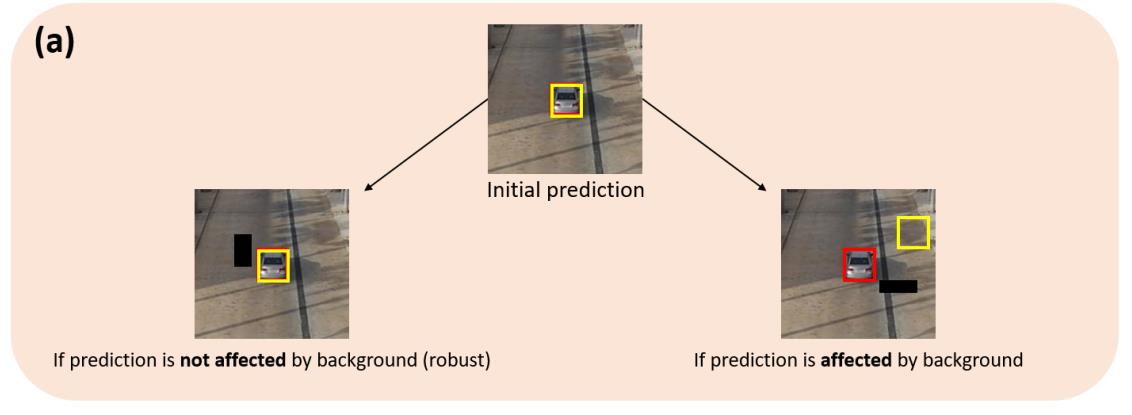
(1) Baseline tracker using random erasing.
Method: Erase a random small rectangular areas of image to confirm whether the prediction is reliable.
Evaluation:I hope it works.
(2) Global search using random searching.
Method: First, we create global searching templates with a predetermined interval. Next, we adaptively determine the number of searches according to the ratio of the image size to the target size. Then, an object is detected within a randomly selected searching area.

(3) Score penalty.
However, the probability of an object disappearing and suddenly appearing at a distant location is very low. To prevent this sudden detection, we penalize a confidence score through spatio-temporal constraints, which is expressed as follows:
![]()
The details of some long-term trackers.
1 . SiamX: An Efficient Long-term Tracker Using Cross-level Feature Correlation and Adaptive Tracking Scheme.
The key is “ADAPTIVE TRACKING SCHEME”.
(1)Momentum Compensation.
Exploit the concept “fast motion” to judge whether the target object is lost.
“If the target displacements between consecutive frames exceeds target sizes, it considers the target object is at a fast-moving state. To avoid targets leaving the search regions, the search center drifts in the direction of momentum:”
conclusion: Fake paper. Its codes lack the long-term tracker.
2. Combining complementary trackers for enhanced long-term visual object tracking.
Running two trackers.
But we can use its score’s method to re-detect.
3. GUSOT: Green and Unsupervised Single Object Tracking for Long Video Sequences
if s1(f∗, x1) > s1(f∗, x2) and s2(f∗, x1) ≤ s2(f∗, x2) :
re-detect else: continue.
Key: motion residual. The key is “UHP-SOT”
4. High-Performance Long-Term Tracking with Meta-Updater
(1) appearance model (lstm)
(2) re-detection( the flag of DiMP ? )
Conclusion: Another fake paper. The most important point is DIMP !
5. UHP-SOT: An Unsupervised High-Performance Single Object Tracker(2017)
Methods: It has three trackers:
(1) Trajectories-based box prediction ( principal component analysis)
(2) Background motion modeling ( optical flow)
(3) Appearance model (normal tracker)
6. Object Tracking Using Background Subtraction and Motion Estimation in MPEG Videos (2005)
Key: Using four corner to compute the motion of background(Optical flow).
7. Fast Object Tracking Using Adaptive Block Matching(2005)
Key: Exploiting ‘Mode filter’ in order to straighten up noisy vectors (Optical flow) and thus eliminate this problem.