・chainerにてついて少し学んだ。
・datasetの中身を書き換えて再度学習


・これから顔の下半分を白にして学習してみます。

・chainerにてついて少し学んだ。
・datasetの中身を書き換えて再度学習
・これから顔の下半分を白にして学習してみます。
{{unknown}}
前半:張研卒業旅行(1回目)

後半:LSTMをちょっと勉強して、実装(知識不足で多変量の時のバッチ化がまだできていないけど時間がhissの論文まで時間がないので、とりあえずバッチ化なしで学習させて最終論文を提出する予定)
・相談
内定先の配属面談が、12/1(水)の16:45~17:15であるので、ゼミ室を使いたいです。
・今後やること
・HISSフルペーパー執筆、ポスター作成、ショートプレゼン動画作成
・ジャーナル執筆開始
・全体ゼミ用の準備
明専スクールの受講。
pytorch学習済みモデルをTensorRT(Nvidiaデバイス向け高速推論モデル)に変換、推論。
GitLabに収集画像データ、スクレーピングプログラムをpushした。
https://mountain.elcs.kyutech.ac.jp/mito/master_thesis_2021
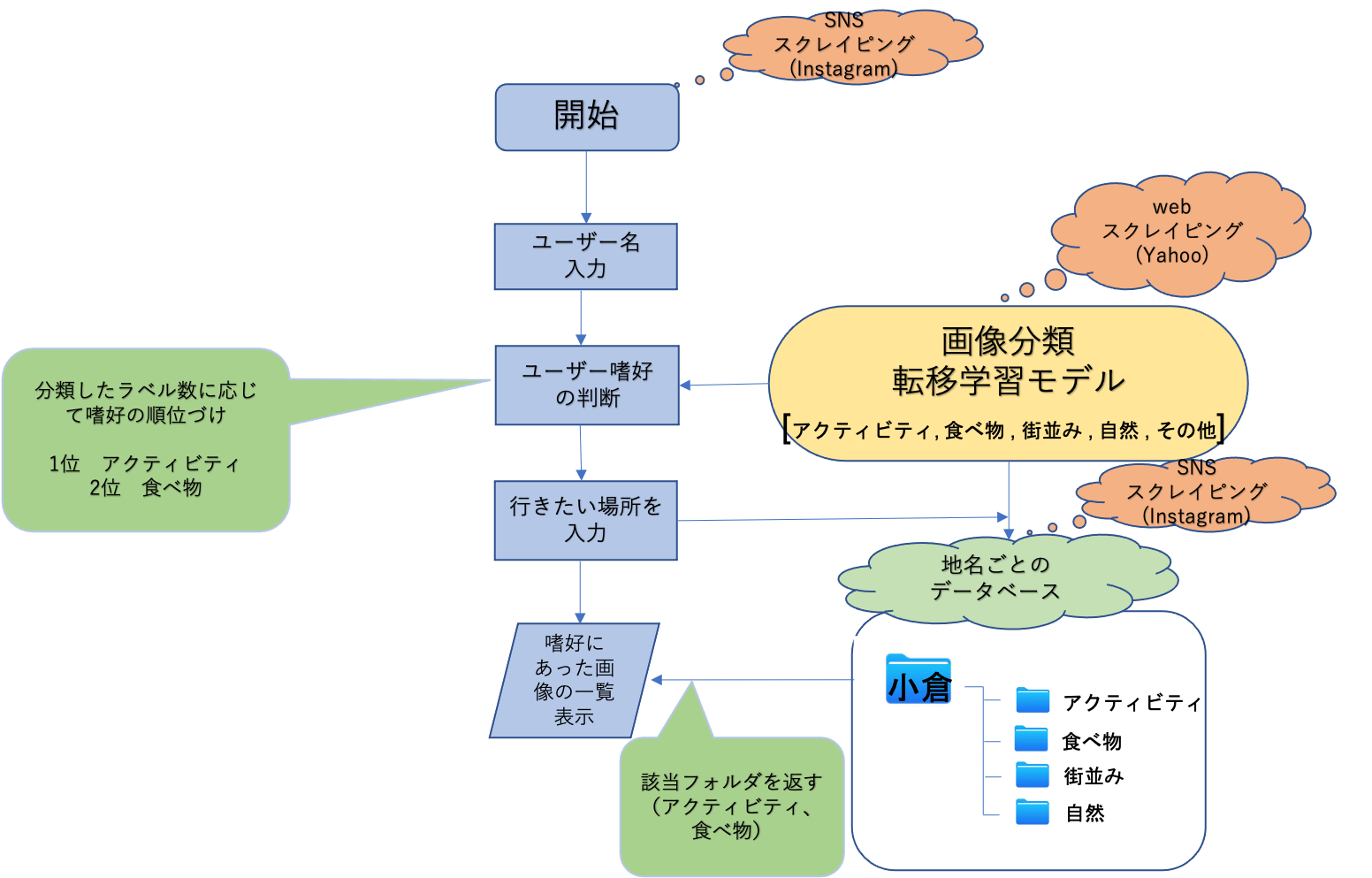
システム全体のフローチャート作成中。
データベースの勉強。
・明専スクールを修了しました。
・全体ゼミのためのパワポを作り始めました。
SSDをもう一度学習するためのデータセット作成中。アノテーション頑張ります。。。
学部から引き継いでいる研究の修士でのタイトルを決めたい、、、
学部のタイトル「視覚障害者が無介助で店頭の商品を識別するシステムの提案」
去年のM2の先輩方の修論を読みたいのですがどこから読めますか
git labとNext Cloudで見つかりませんでした。
・長回しで取ったmp4ファイルを自動で分割するプログラムを作成
mp4ファイルにMediaPipe Handsを使うことで手を認識し、ジェスチャーの開始フレームと終了フレームを求め、ジェスチャーごとのmp4ファイルに分割
・自分で集めたデータを学習、ファインチューニングありとなしで検証
学習に使ったデータ:カメラ1台で撮影、10種類のハンドジェスチャーをそれぞれ20回ずつ
精度はどちらも100%になりましたが、t-SNEで可視化したものやcos類似度を見ると、ファインチューニングなしで学習したものは本質的に動作の特徴を学習できておらず、今回集めたジェスチャーのデータに過学習しているように見えます。
ファインチューニングによる負の転移は今のところ起きてないようなので、ファインチューニングが有効であるという前提で研究を続けます。
3~4歩程度の動画で40個のデータを作成。現在、7人分収集した。
合計280個で70%をtrain(196), 20%をval(56), 10%をtest(28)データとした。
白黒の動画にしたかったが、あまりうまくいかなかった(動画をなぜかのせれなかったので、スクショ)
import cv2
# 動画読み込みの設定
movie = cv2.VideoCapture('3.mp4')
# 動画ファイル保存用の設定
fps = int(movie.get(cv2.CAP_PROP_FPS)) … Continue Reading ››