テーマ「文字認識を用いた買い忘れ防止案」
今週の進捗
・買い物前に登録した商品名とレシートから読み取った商品名のマッチングのため、レシートから読み取った商品名から類語を抽出し、抽出された言葉と登録した商品名が合致していれば「この商品は購入した」と認識させるようにしたいと考えた。そのために、自然言語用の学習モデルについて調べ、fastTextが良さそうだと思い、fastTextをインストールしようとしたが、fastTextをインストールする前にMecab,Cygwinなどをインストールする必要があったので、現在はそれらのインストールに時間を取られています。
https://qiita.com/yakipudding/items/e798614ca833d264abf3
今後の課題
・fastTextで上記のことができそうなのであれば、fastTextの学習用データをどうするのか考える。
赤外線照射機を用いて撮影をおこなった。
50m先の人物の認識は周りの影響もあり最初から取り組むには現実的ではないと考えた。
60キロで走行時でも停止できるように50m先の人を認識させることを目標としていたが、現実的な30〜40m先の人物の認識から行おうと思う。


OpenCVとdlibを用いた視線検出プログラムを動作させた。
目の検出はうまく行えているが、瞳を検出しない場合が多かった。また瞳を検出した時も視線が変な方向を示すことがあった。
- DL-Boxのデータ整理、自分のパソコンに研究データ(200GB)を移した。今後、外付けハードディスクに移す予定。
- DL-BoxでKerasを使えるように環境を構築した。(KerasのAPIが優秀なため)
進捗
評価関数にレーベンシュタイン距離を適用したプログラムを実装・実行した。図4・図5にそれぞれ図1・図2を用いた場合の文字認識結果を示す。図4・図5のLev_valueは各文字列の認識結果と目標文字列とのレーベンシュタイン距離の合計値である。フィルターを使用しない場合のLev_valueが11.45であるのに対して、最優秀個体のフィルターを用いた場合は3.84と、約66%の改善が認められた。
-
 図1.入力画像
図1.入力画像
-
 図2.最優秀個体による出力画像
図2.最優秀個体による出力画像
-
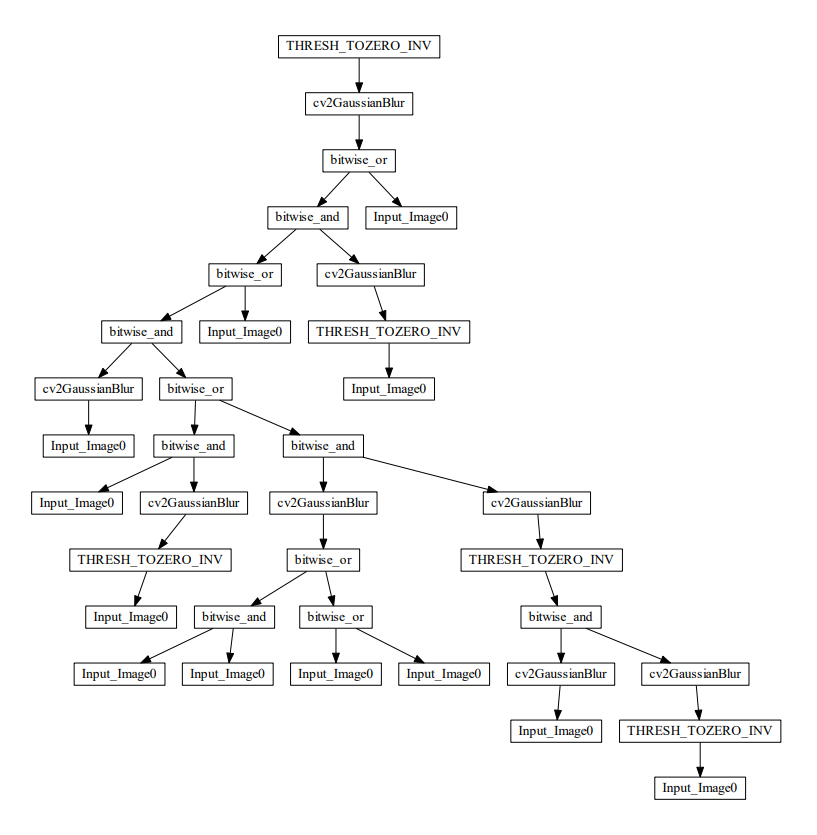 図3.最優秀個体の木構造
図3.最優秀個体の木構造
-
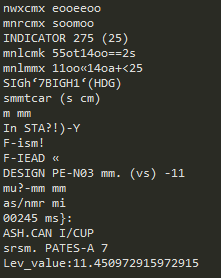 図4.図1を用いた場合の文字認識結果
図4.図1を用いた場合の文字認識結果
-
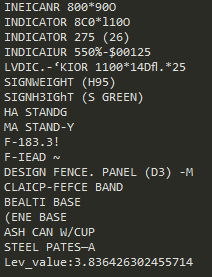 図5.図2を用いた場合の文字認識結果
図5.図2を用いた場合の文字認識結果
sckit learnに付属している手書き文字をSVMで分類した。
学習、評価、パラメーターチューニングについて大体理解した。
次週は自分の画像でやってみる。
画像にラベルを付けるやり方がわからないので調べる。(画像の名前からラベルを付けるやり方を試してるが、画像を箱にいれるとこでつまづいている。)
とりあえず黒点とさびの2つを判別できるようにする。
今週の進捗
- 歩行者の再識別(ReID): Deep learning person re-identification in PyTorch, モデルトレーニングが完了し,合計時間かかります:11days,3:15:55
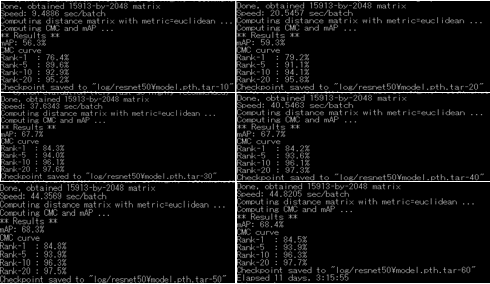 モデルトレーニング
モデルトレーニング
- する対応する記事を読む《Omni-Scale Feature Learning for Person Re-Identification》。
金當:アンドロイドアプリを作成するための学習、取り敢えずJAVAで作成し、画像処理デモを一個作る。
井上:英語の学習を強化。VibraImageで不審者の検出に関する論文を閲覧。CNNの勉強を継続中。研究テーマ:もう少し検討する。
梶岡:顔画像から、飲酒の有無を判断する基礎実験を行う。
〇今週の進捗
- 参考書 終わった
- 顔から血中アルコール濃度を測定する論文自体はなさそう
〇今後の課題
- 新しい参考書を買った、アプリを実際に作っていきたい
- 修士の研究は新しいものにするか、自分で考えてやっていくか検討中
進捗
- TOEICの勉強
- VibraImageに関する論文を読んだ
→ DEFENDER-X は、顕在的な心理状態や心理特性を測定する心理尺度とは別のものを測定しており、心理状態や心理特性を測定する心理尺度とも別のものを測定している可能性があることが分かった
- 研究テーマの調査
課題
Stay Hungry, Stay Foolish!
