The long term object tracker requires the tracker to be able to retrieve lost targets. So I want to predict the possible locations where the target might appear based on the historical motion trajectory of the object. Trajectory prediction requires the camera motion and current object tracking method can’t provide camera information,such as camera pose or motion.
In order to get depth map and camera poses, I am reading papers about slam with monocula camera, involving unsupervised learning.
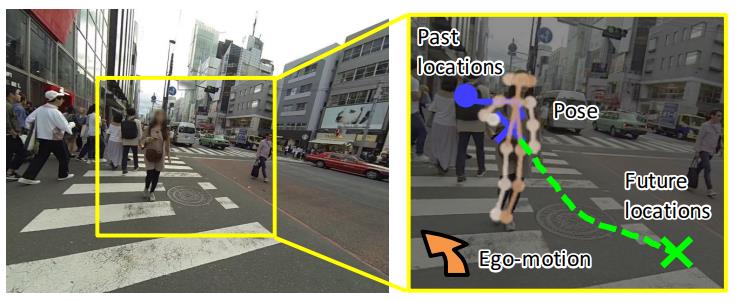
- Future Person Localization in First-Person Videos
Purpose: predicting future locations of people observed in first-person videos.
key point :a) ego-motion b) Scales of the target person. c) KCF for tracking d) feature concatenating.
evaluation: Excellent introductory work. But how to get ego-motion information?
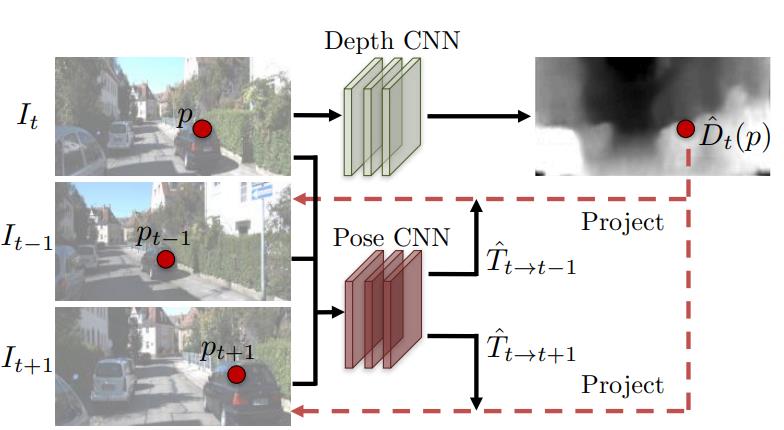
2. Unsupervised Learning of Depth and Ego-Motion from Video
Purpose: Presenting an unsupervised learning framework for the task of monocular depth and camera motion estimation from unstructured video sequences.
Key point: a) Visual synthesis b) unsupervised learning.
Evaluation: Nice paper. But it still need camera intrinsics.
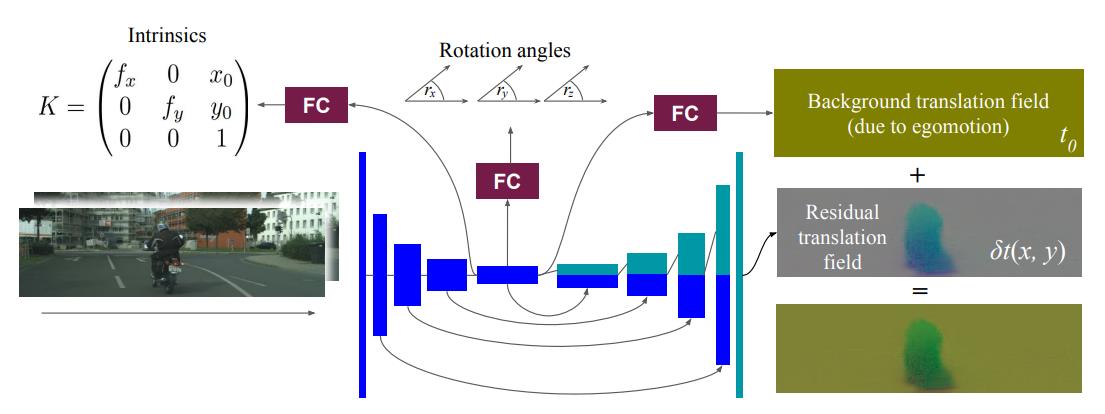
3. Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras
Purpose: Presenting a novel method for simultaneously learning depth, egomotion, object motion, and camera intrinsics from monocular videos, using only consistency across neighboring video frames as a supervision signal.
Key opint: a) Generating camera intrinsics.
Evaluation: Nice paper. Rrovide code. But it may be too slow.