
面接があるためゼミはお休みします。
日別アーカイブ: 2024年7月11日
今週の進捗(根来)
本日は私用のためゼミ欠席します。
一応セグメンテーションできました。次はマッピングができるようにやっていこうと思ってます。
今週の進捗(藤本)
今週はずっとバイトしてたので進捗は全然無いです。
週報
- Read an Book 《Science Research Writing》
- Swimming
- Paper method code got one star on Github! Maybe will get one cite soon!
週報(SUN YUYA)
(1) I am training the model after exchanging the tracking datasets with the trajectory datasets.
(2) I am reading the paper about dense optical flow, trying to find a simple method to compute background motion.
Paper Link: https://arxiv.org/pdf/2305.12998v2
(3) I am still making a GUI to compare multiple Super Mario RL agents.
週報_BEVFormer(QI)
BEVFormer:Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
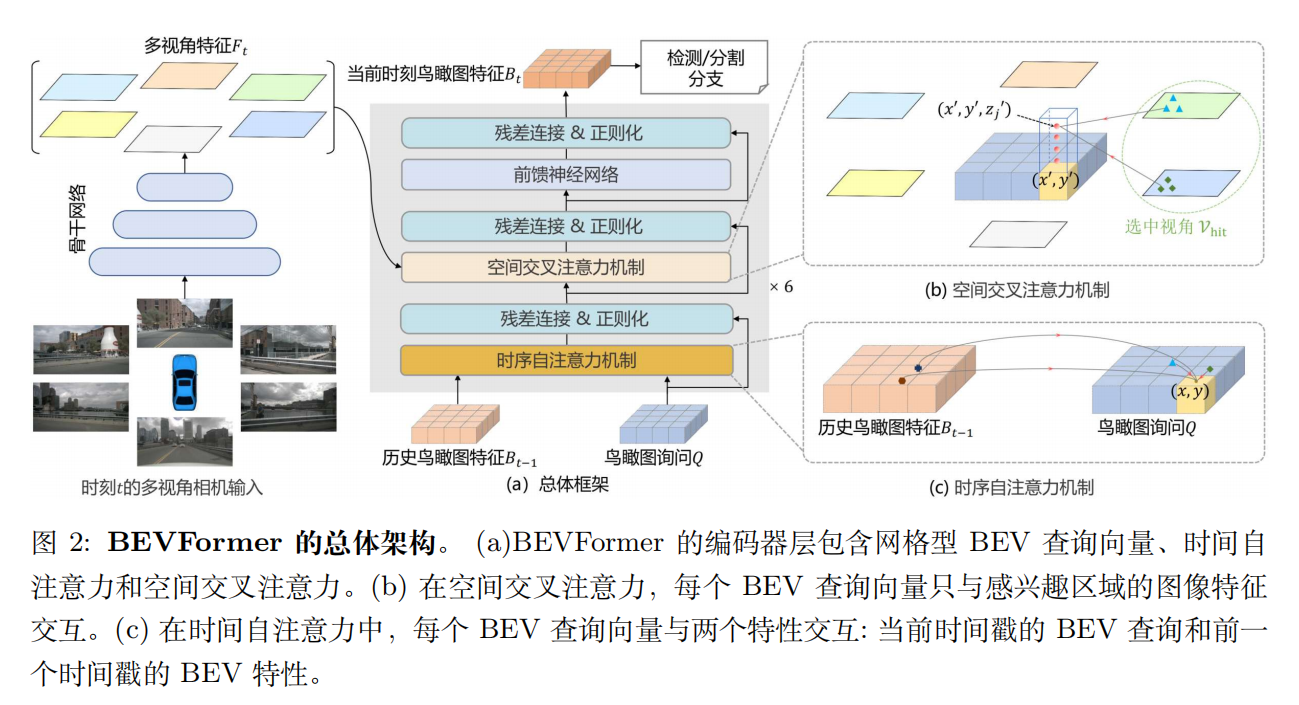
Learning the BEVFormer algorithm which based on VPN and LSS.
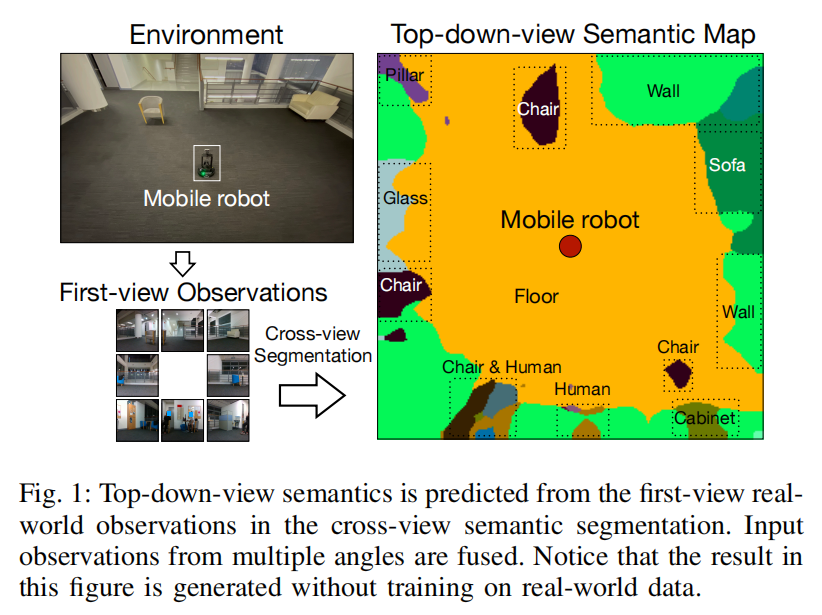
Cross-view Semantic Segmentation for Sensing Surroundings
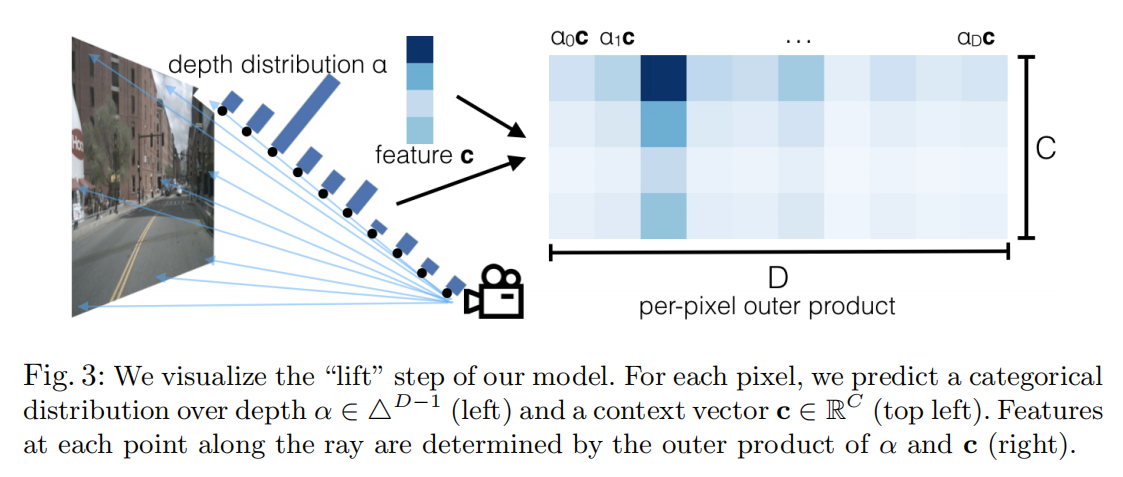
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
The output multi-scale features from FPN with sizes of 1/16, 1/32, 1/64 and the dimension of C = 256 . For experiments on nuScenes, the default size of BEV queries is 200×200, the perception ranges are [−51.2m, 51.2m] for the X and Y axis and the size of resolution s of BEV’s grid is 0.512m.