(1) I am training the model after exchanging the tracking datasets with the trajectory datasets.
(2) I am reading the paper about dense optical flow, trying to find a simple method to compute background motion.
Paper Link: https://arxiv.org/pdf/2305.12998v2
(3) I am still making a GUI to compare multiple Super Mario RL agents.
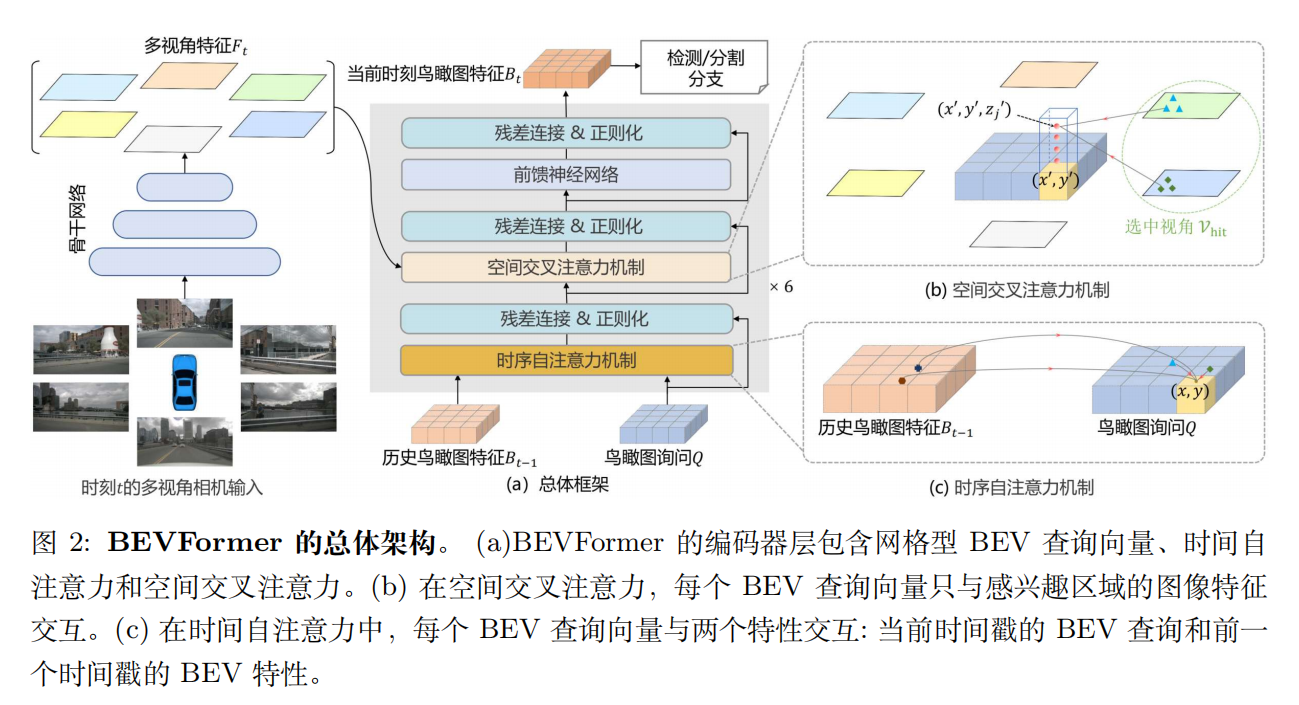
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
Learning the BEVFormer algorithm which based on VPN and LSS.
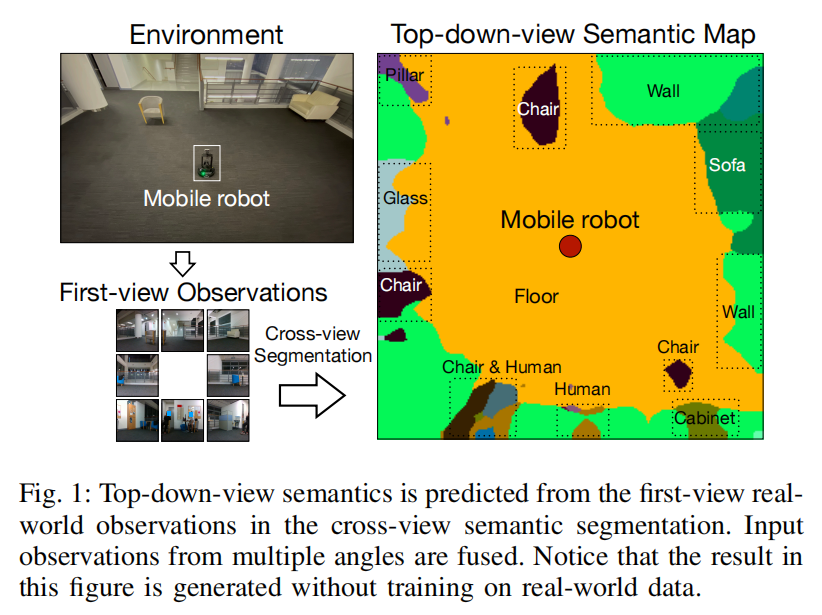
Cross-view Semantic Segmentation for Sensing Surroundings
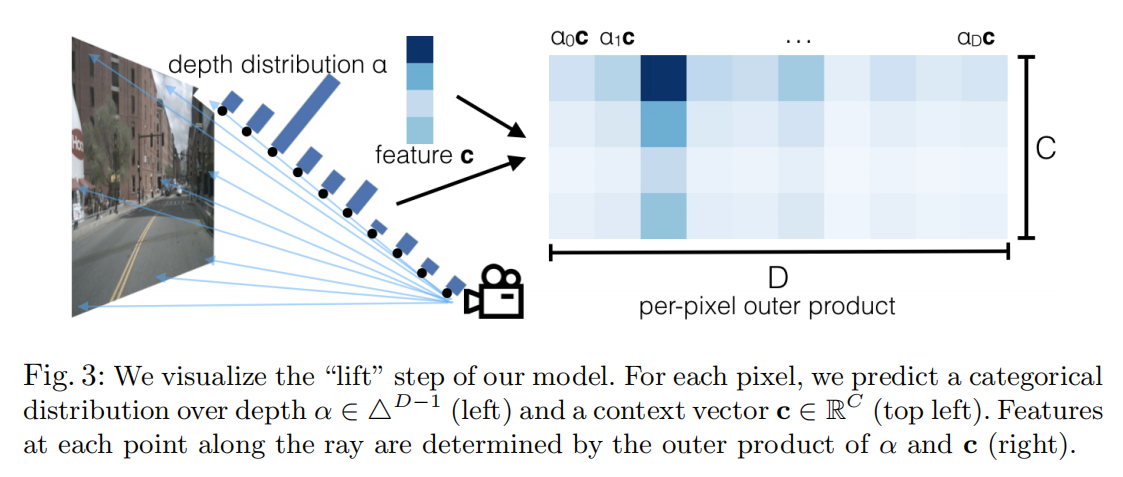
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
The output multi-scale features from FPN with sizes of 1/16, 1/32, 1/64 and the dimension of C × 200, the perception ranges are [− 51.2m, 51.2m] for the X Y s of BEV’s grid is 0.512m.
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
BEVFormer-中文版.pdf
村田製作所の面接を受けたが微妙だった。日本製鉄に合格した、千葉の富津ってところに配属になった。先週から夏インターンに向けた就活が落ち着いたので、たくさん筋トレできた。
日本語能力試験N1を受けました。
インターンに落ちたので、SPIの点数が低かったことが原因だと思います。今からSPIや玉手箱の練習をしたいと思います。
また、面接のことを少し心配しているので、冬のインターンまでに話すことをもっと練習したいと思います。
先週は、富士通、パナソニック、京セラの面接がんばりました。オービックのインターンシップに合格しました。
今週は、たまった課題とdjangoで日記アプリの作成にとりかかります。
先週はデンソーの適性検査、AGCの面接を受けた。
富士電機のインターンが決まった。
SONYの適性検査を受けましたが、あまりできませんでした。
今週はSONYの面接を受けて、本格的にスマプロに取り掛かりたいです。
NECのES合格しました。次は面接です。頑張ります。たぶんNSSOLの適性検査も合格してると思います。
学生プロジェクトは日記のアプリを使ってDjangoの勉強をしました。
院試が終了し少し休憩してしまいました.今週から具体的なシステムについて使用技術などを検討していきたいと思います.
投稿ナビゲーション
Stay Hungry, Stay Foolish!