中心窩画像処理の円モデル、楕円モデル、視野特性に基づいた楕円モデルを完成させました。
現在は視覚的に優れているWeierらの線形モデルを作っています。円形モデルは完成して楕円モデルを作っているところです。

中心窩画像処理の円モデル、楕円モデル、視野特性に基づいた楕円モデルを完成させました。
現在は視覚的に優れているWeierらの線形モデルを作っています。円形モデルは完成して楕円モデルを作っているところです。
・別日に取ったデータを使いモデルの評価
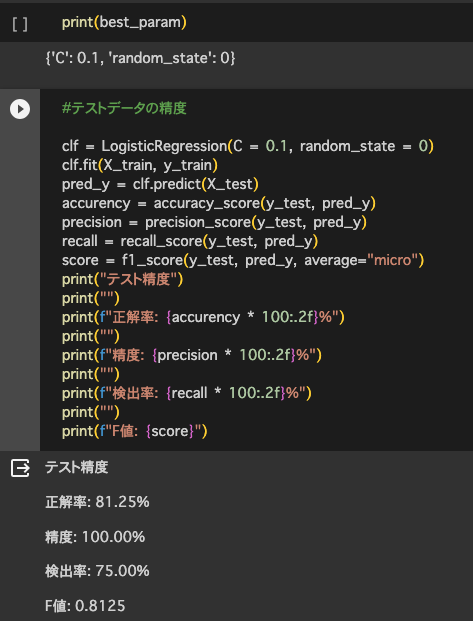
→ロジスティック回帰
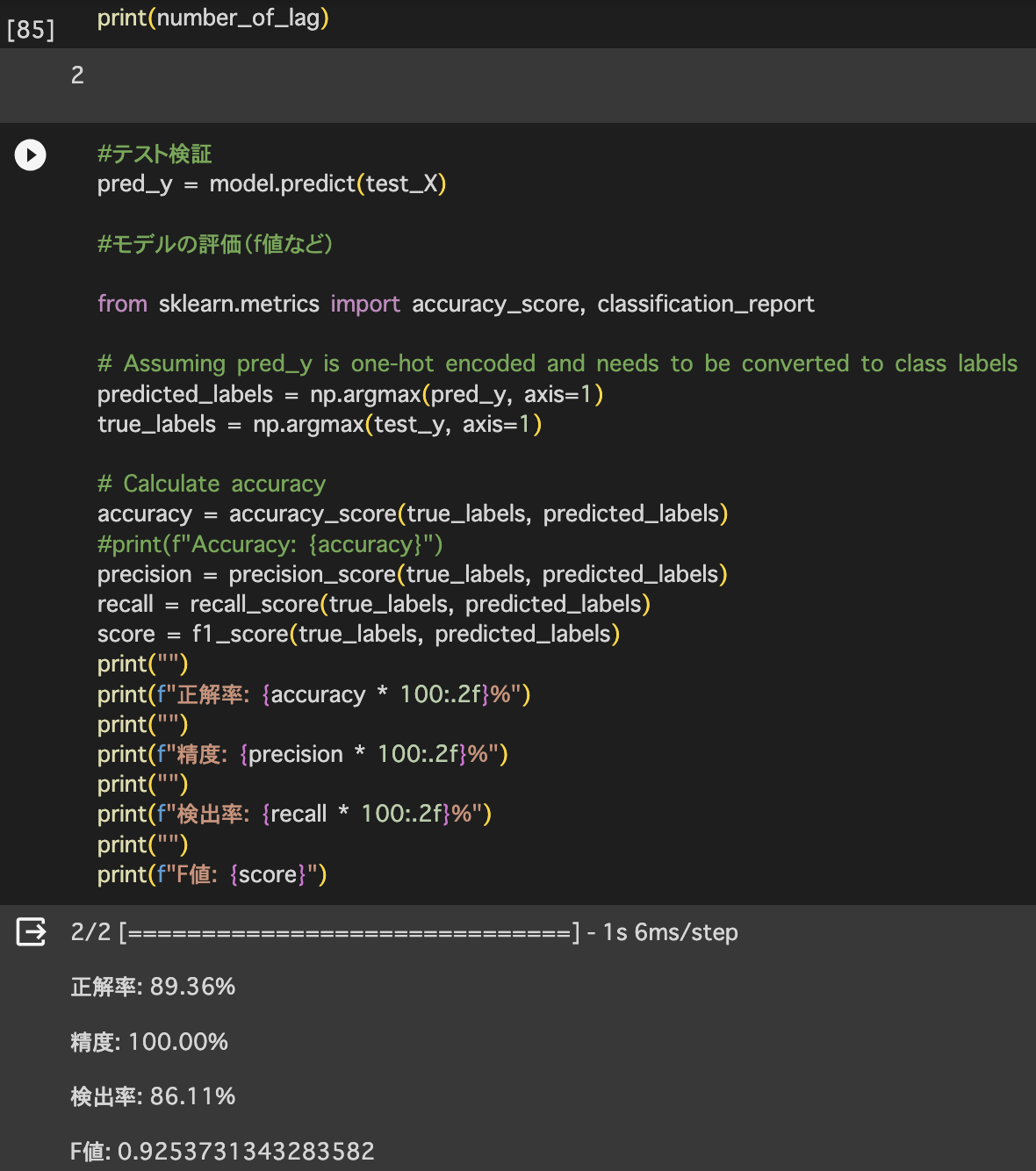
We find a lot of methods of re-detection about Long term object tracking.
1 . ‘Skimming-Perusal’ Tracking: A Framework for Real-Time and Robust Long-term Tracking
The re-detection method:
After obtaining the best candidate in each frame, our tracker treats the tracked object as present or absent based on its confidence score and then determines the search state (local search or global search) in the next frame.
Key: Training a deep network(Verifier).
similarity
2 . SiamX: An Efficient Long-term Tracker Using Cross-level Feature Correlation and Adaptive Tracking Scheme
The re-detection method:
Exploiting threshold score.
3 . Combining complementary trackers for enhanced long-term visual object tracking
Running two trackers.
Training a deep network to decide when to re-detect.
4 . GUSOT: Green and Unsupervised Single Object Tracking for Long Video Sequences
Background motion estimation to predict location.
Evaluating two bboxes.
4 . High-Performance Long-Term Tracking with Meta-Updater
input: socre, response map, target object, template
model: lstm
output: score
5. MFT: Long-Term Tracking of Every Pixel
Optical flow is very important.
6. Multi-Template Temporal Siamese Network for Long-Term Object Tracking
Predicting trajectoyies.
The re-detection method:
Input: distance error
Output: Reliability Score
7. Multi-Template Temporal Siamese Network for Long-Term Object Tracking
Predicting trajectoyies.
The re-detection method:
Input: distance error
Output: Reliability Score
8. Robust Long-Term Object Tracking via Improved Discriminative Model Prediction
We augment various backgrounds that are not included in the search area to train a more robust model in the background clutter.
9. Robust Long-Term Object Tracking via Improved Discriminative Model Prediction
We augment various backgrounds that are not included in the search area to train a more robust model in the background clutter.
10. Target-Aware Tracking with Long-term Context Attention
The re-detection method:
P-mean_score:
11. Unifying Short and Long-Term Tracking with Graph Hierarchies
Difficult to understand.
Solved the problems that the Spconv cannot be compiled:

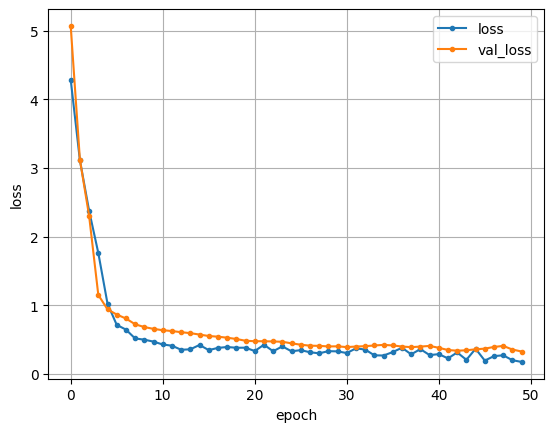
Training the total dataset(nuScenes, 442.8GB) on RTX3090Ti cost me about 4 days.
![]()
Achieved the test results:
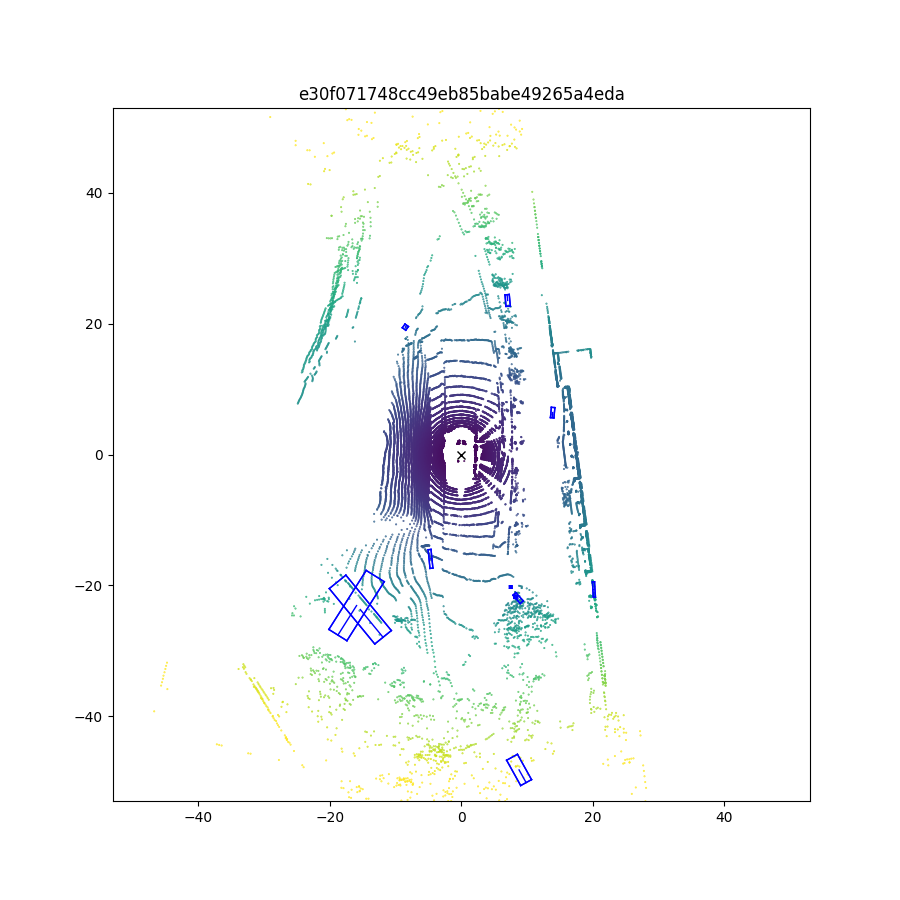

The result trained on my computer is almost similiar to the official result. Next, I will look for some advanced methods to modify the CenterPoint.
Recently, I was learning mmdetection3D.
This week I continue conducting experiments about long term tracking. Except for the experiments, I am ready for reading some important papers about long term tracking.
1. CoTracker: It is Better to Track Together
The paper’s purpose:
(1) Tracking points individually ignores the strong correlation that can exist between the points, for instance, because they belong to the same physical object, potentially harming performance.
Contributions:
(1) In this paper, we thus propose CoTracker, an architecture that jointly tracks multiple points throughout an entire video.
(2)It is based on a transformer network that models the correlation of different points in time via specialised attention layers. The transformer iteratively updates an estimate of several trajectories.
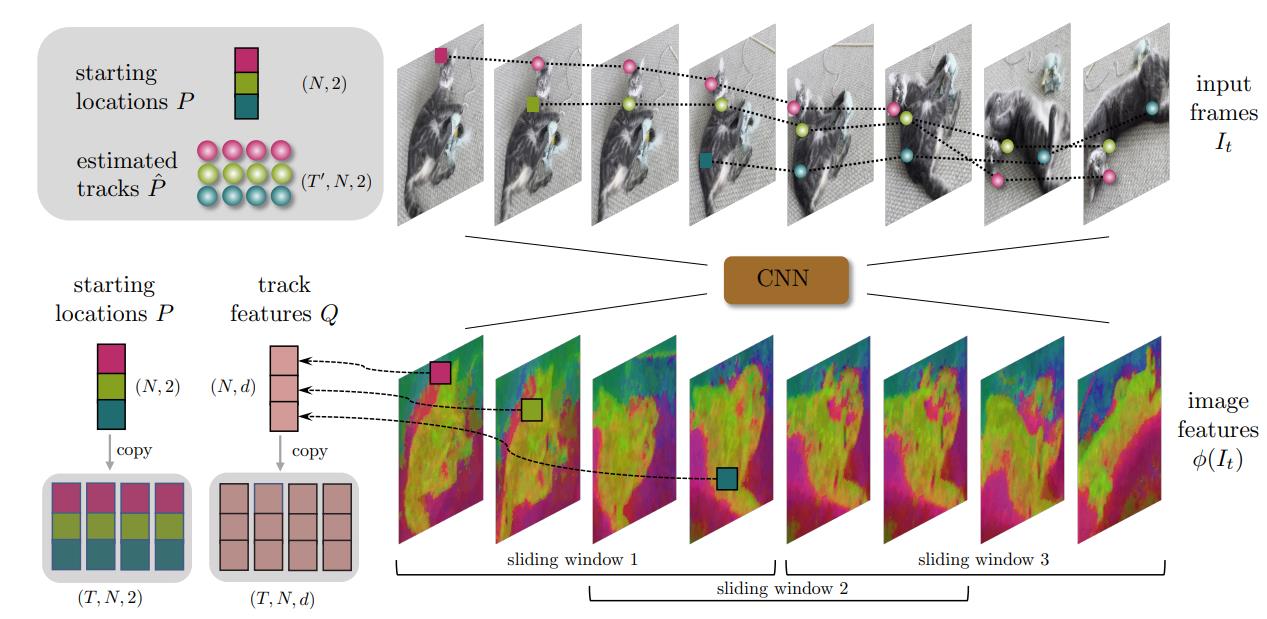
Personal Evaluation:
Release code. Very important. The innovation points are very innovative.The paper is related to optical flow and tragectory. We may use this paper to find the of motion of environment.
2. Boosting UAV Tracking With Voxel-Based Trajectory-Aware Pre-Training
The paper’s purpose:
(1)To slove the problem that the siamese tracker was trapped when facing multiple views of object in consecutive frames.
(2)The general image-level pretrained backbone can overfit to holistic representations, causing the misalignment to learn object-level properties in UAV tracking.
Contributions:
(1) Fully exploit the stereoscopic representation for UAV tracking. Specifically, a novel pre-training paradigm method is proposed.
(2) Through trajectory-aware reconstruction training (TRT), the capability of the backbone to extract stereoscopic structure feature is strengthened without any parameter increment.

Personal Evaluation:
No code. The paper is related to 3D tracking.
3. RSPT: Reconstruct Surroundings and Predict Trajectories
for Generalizable Active Object Tracking
The paper’s purpose:
(1) However, building a generalizable active tracker that works robustly across different scenarios remains a challenge, especially in unstructured environments with cluttered obstacles and diverse layouts.
Contributions:
(1) To address this challenge, we present RSPT, a framework that forms a structure-aware motion representation by Reconstructing the Surroundings and Predicting the target Trajectory.

Personal Evaluation:
No code. Don’t know how to exploit this paper.
4. Visual Prompt Multi-Modal Tracking
The paper’s purpose:
(1) Trajectory prediction.
Contributions:
(1)ARTrack tackles tracking as a coordinate sequence interpretation task that estimates object trajectories progressively, where the current estimate is induced by previous states and in turn affects subsequences.
(2)This time-autoregressive approach models the sequential evolution of trajectories to keep tracing the object across frames, making it superior to existing template matching based trackers that only consider the per-frame localization accuracy.

Personal Evaluation:
Release code. Worth reading.
5. Global Instance Tracking: Locating Target More Like Humans
The paper’s purpose:
(1)The massive gap indicates that researches only measure tracking performance rather than intelligence.
(2) Occlusion and fast motion.
Contributions:
(1) In this article, we first propose the global instance tracking (GIT) task, which is supposed to search an arbitrary user-specified instance in a video without any assumptions about camera or motion consistency, to model the human visual tracking ability.
(2) Whereafter, we construct a high-quality and large-scale benchmark VideoCube to create a challenging environment.
(3) Finally, we design a scientific evaluation procedure using human capabilities as the baseline to judge tracking intelligence.
(4) Additionally, we provide an online platform with toolkit and an updated leaderboard.

Personal Evaluation:
A new dataset benchmark. Maybe it’s very important.
6. Continuity-Aware Latent Inter frame Information Mining for Reliable UAV Tracking
The paper’s purpose:
(1) Mainly focuses on explicit information to improve tracking performance, ignoring potential interframe connections.
Contributions:
(1) A network can generate highly-effective latent frame between two adjacent frames.
(2) Fully explore continuity-aware spatial-temporal information.
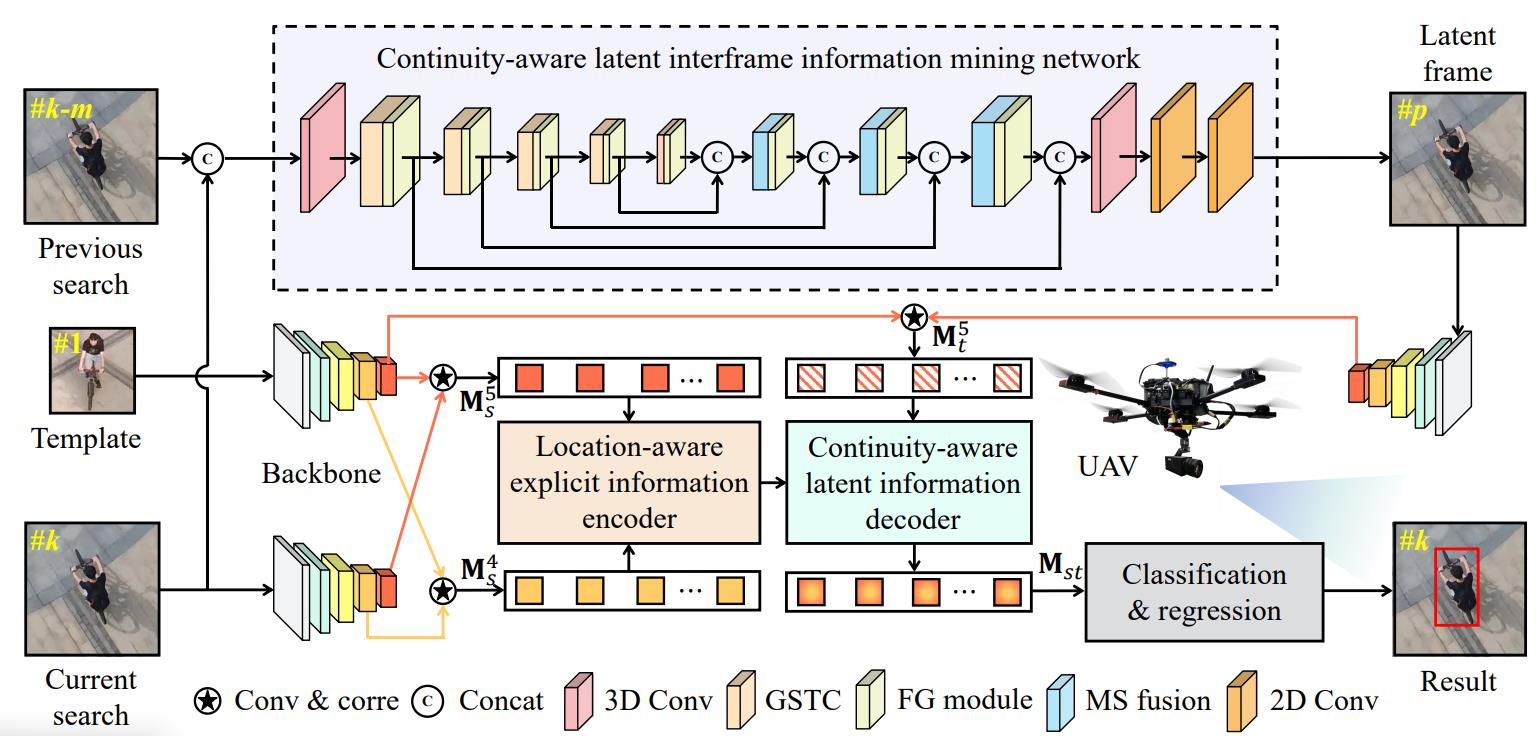
Personal Evaluation:
Release code. The innovation points are very innovative.
7. DropMAE: Masked Auto-encoders with Spatial-Attention Dropout for Tracking Tasks
The paper’s purpose:
(1) MAE (masked autoencoder ) heavily relies on spatial cues while ignoring temporal relations for frame reconstruction.
Contributions:
(1) DropMAE adaptively performs spatial-attention dropout in the frame reconstruction to facilitate temporal correspondence learning in videos.
(2) Improving the pre-training process.
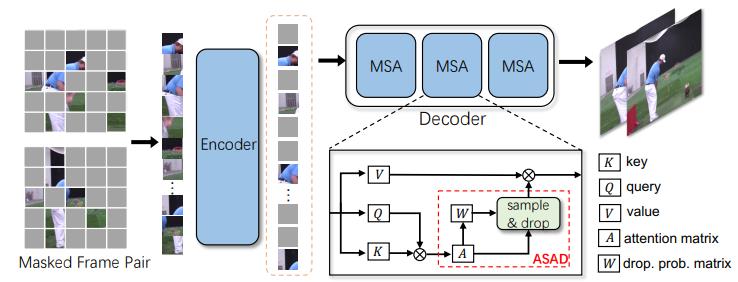
Personal Evaluation:
Release code. The innovation points are very innovative. I can’t understand the paper.
8. Learning Historical Status Prompt for Accurate and Robust Visual Tracking
The paper’s purpose:
(1) However, they struggle to make prediction when the target appearance changes due to the limited historical information introduced by roughly cropping the current search region based on the predicted result of previous frame.
(2) The incapacity to integrate abundant and effective historical information.
Contributions:
(1) HIP is a plug-and-play module that make full use of search region features to introduce historical appearance information.
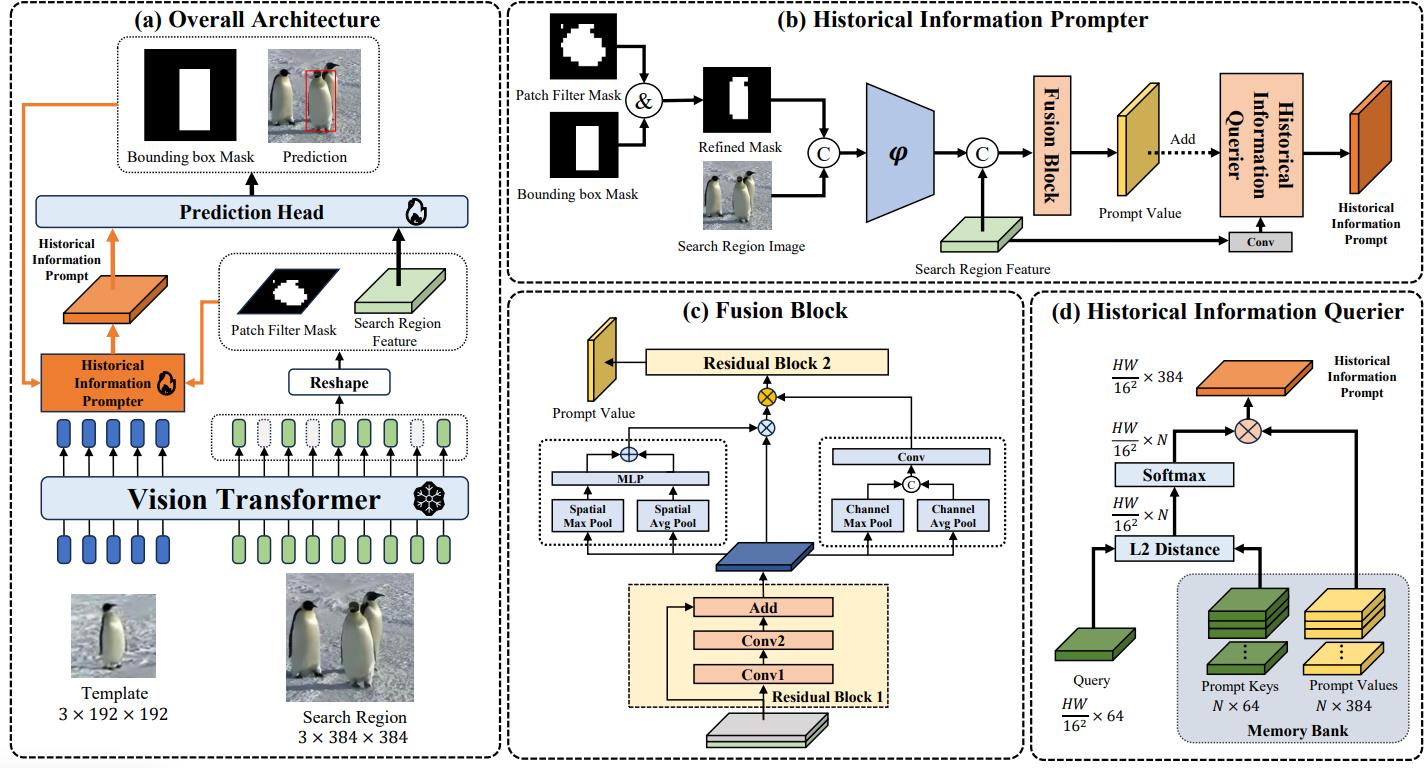
Personal Evaluation:
No code. How to produce mask in tracking ?
9. Lightweight Full-Convolutional Siamese Tracker
The paper’s purpose:
(1) The current tracking model is too big.
Contributions:
(1) LightFC employs a novel efficient cross-correlation module (ECM) and a novel efficient rep-center head (ERH) to enhance the nonlinear expressiveness of the convolutional tracking pipeline.
(2) Additionally, it references successful factors of current lightweight trackers and introduces skip-connections and reuse of search area features.
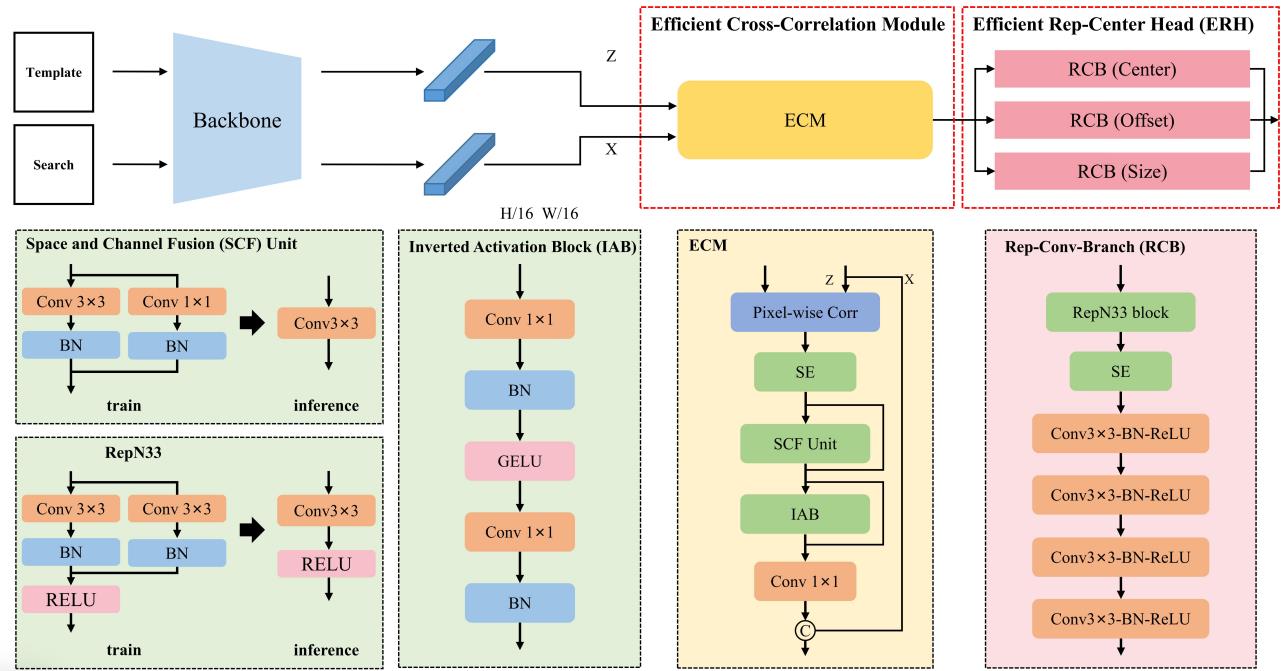
Personal Evaluation:
Release code. Another fast tracker. Worthing reading.
10. LiteTrack: Layer Pruning with Asynchronous Feature Extraction for Lightweight and Efficient Visual Tracking
The paper’s purpose:
(1) Too big and too slow.
Contributions:
The main innovations of LiteTrack encompass:
(1) Asynchronous feature extraction and interaction between the template and search region for better feature fushion and cutting redundant computation.
(2) Pruning encoder layers from a heavy tracker to refine the balance between performance and speed.

Personal Evaluation:
Release code. Another fast tracker. Worthing reading.
11. MixFormerV2: Efficient Fully Transformer Tracking
The paper’s purpose:
(1) Too slow.
Contributions:
(1) Our key design is to introduce four special prediction tokens and concatenate them with the tokens from target template and search areas.
(2)Then, we apply the unified transformer backbone on these mixed token sequence.
(3) Based on them, we can easily predict the tracking box and estimate its confidence score through simple MLP heads.
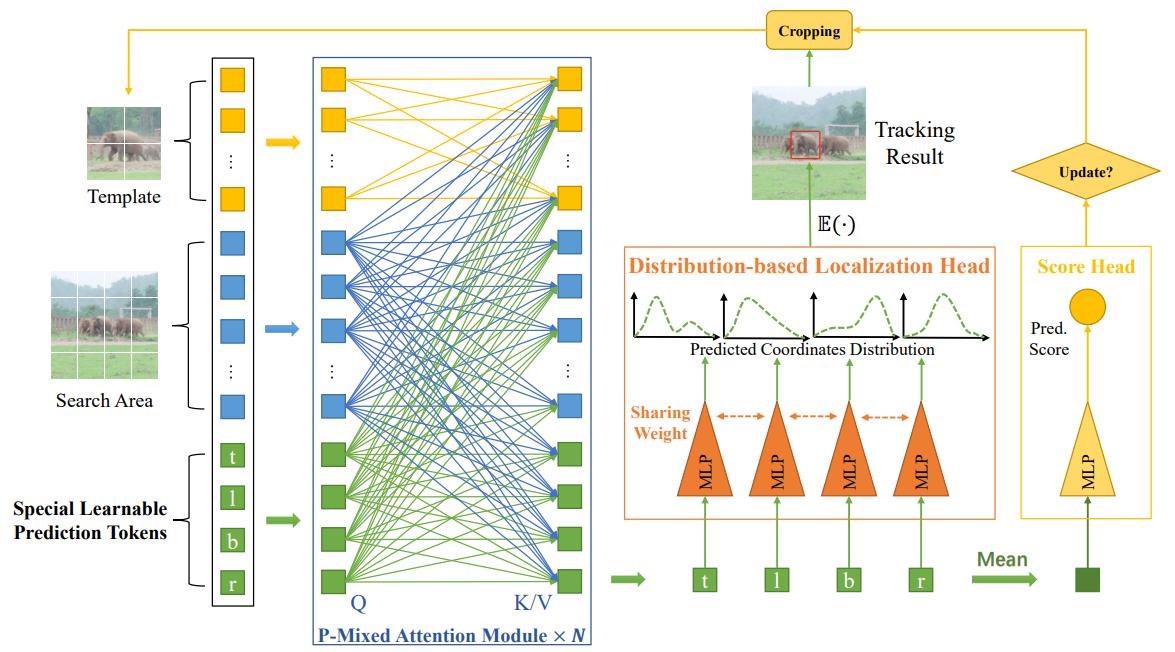
Personal Evaluation:
Release code. Another fast tracker. Worthing reading.
12 .Mobile Vision Transformer-based Visual Object Tracking
The paper’s purpose:
(1) Too slow and too big.
Contributions:
The main innovations of LiteTrack encompass:
(1) We propose a lightweight, accurate, and fast tracking algorithm using Mobile Vision Transformers (MobileViT) as the backbone for the first time.
(2) We also present a novel approach of fusing the template and search region representations in the MobileViT backbone, thereby generating superior feature encoding for target localization.

Personal Evaluation:
Release code. Another fast tracker. Worthing reading.
13. SeqTrack: Sequence to Sequence Learning for Visual Object Tracking
The paper’s purpose:
(1) It casts visual tracking as a sequence generation problem, which predicts object bounding boxes in an autoregressive fashion.
Contributions:
(1)The encoder extracts visual features with a bidirectional transformer.
(2)While the decoder generates a sequence of bounding box values autoregressively with a causal transformer.
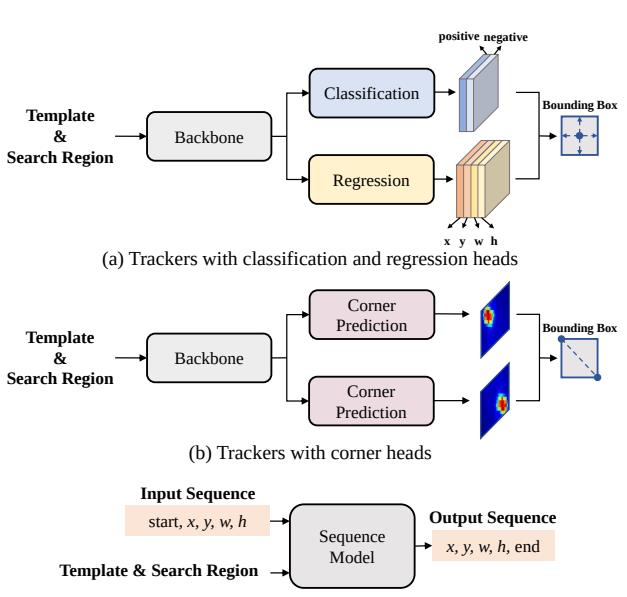
Personal Evaluation:
Release code. Worth reading.
14. SOTVerse: A User-defined Task Space of Single Object Tracking
The paper’s purpose:
(1)The former causes existing datasets can not be exploited comprehensively, while the latter neglects challenging factors
in the evaluation process.
Contributions:
(1)We first propose a 3E Paradigm to describe tasks by three components (i.e., environment, evaluation, and executor).
(2)Then, we summarize task characteristics, clarify the organization
standards, and construct SOTVerse with 12.56 million frames. Specifically, SOTVerse automatically labels challenging factors per frame, allowing users to generate user-defined spaces efficiently via construction rules.
(3) Besides, SOTVerse provides two mechanisms with new indicators and successfully evaluates trackers under various subtasks.
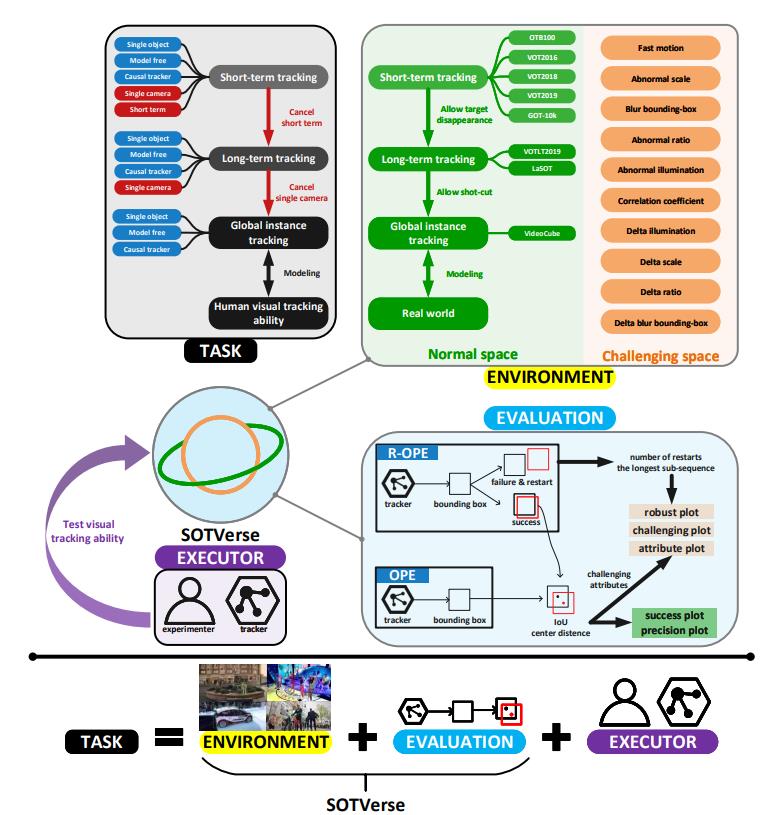
Personal Evaluation:
Release code. Interesting Innovation. Worth reading.
15. Towards Grand Unification of Object Tracking
The paper’s purpose:
(1)We present a unified method, termed Unicorn, that can simultaneously solve four tracking problems (SOT, MOT, VOS, MOTS) with a single network using the same model parameters.
Contributions:
(1) Unicorn provides a unified solution, adopting the same input, backbone, embedding, and head across all tracking tasks.

Personal Evaluation:
Release code. Nice paper. Worth reading.
16. Tracking through Containers and Occluders in the Wild
The paper’s purpose:
(1)Tracking objects with persistence in cluttered and dynamic environments remains a difficult challenge for computer vision systems
Contributions:
(1) We set up a task where the goal is to, given a video sequence, segment both the projected extent of the target object, as well as the surrounding container or occluder whenever one exists.
(2) To study this task, we create a mixture of synthetic and annotated real datasets to support both supervised learning and structured evaluation of model performance under various forms of task variation, such as moving or nested containment.

Personal Evaluation:
Release code. Nice paper. Worth reading.
3匹分の猫の顔のモデルを作成した。顔が映っている画像は基本的に判別できたが、顔が映っていない画像やカメラから猫が遠い画像、ぶれている画像は判別できなかった。この欠点を模様パターンモデルでカバーできれば御の字。
今後は模様パターンのモデルの作成に移りたいと思う。また、モデルとなる猫の種類も増やしていきたい。
・カラー化処理完了
・FERを用いて、表情のラベル付け
データの作成。
↑
FWの場合のみを考えた。{ 年齢の平均、得点合計、アシスト合計、勝ち点平均、先発合計、途中出場合計、出場時間合計、ペナルティカード合計、怪我合計、クラブレベル平均、リーグレベル平均、3年間での市場価格の差} を説明変数にした。データの個数は各ポジションで300~400くらいになる予定。
大ゼミの準備。
・大ゼミのための資料を作成した。
・撮影距離が5mと7mの高解像画像と超解像画像で顔認証できるかを試しみてみた。今週は実際に教室で撮影してみようと思います。