面接
ES作成

面接
ES作成
foveated imaging処理の円形モデル、楕円モデル、視野特性に基づいた楕円モデルを完成させました。
実験では、伝送ビットレートの比較、処理速度の比較、主観画質の評価をしました。主観画質の評価は張研究室の先輩や友達に協力してもらっていて、データを取っている最中です。
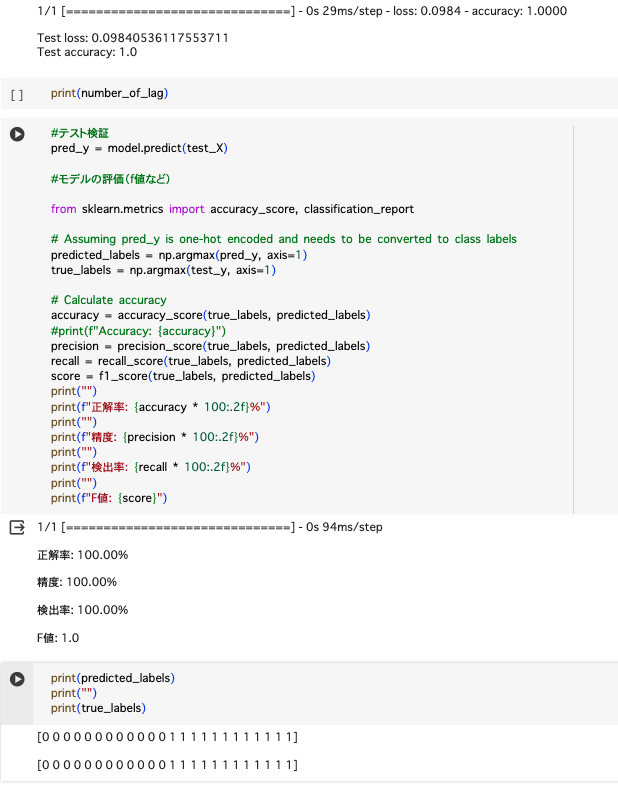
顔認証のプログラムをかきかえて、もう一度各距離ごとの顔認証を試したらうまくいきました。各距離ごとの写真をふやして、2m,4m,6m,8m,での高解像画像と超解像画像での顔認証の精度と顔認証が成功したときの平均の類似度を調べました。8mをこえると顔認証できませんでした。
精度(%)
| 高解像 | 超解像 | |
| 2m | 100 | 100 |
| 4m | 78.94 | 89.74 |
| 6m | 69.23 | 81.21 |
| 8m | 29.17 | 50 |
平均類似度(1に近いほど本人に近い、閾値0.7)
| 高解像 | 超解像 | |
| 2m | 0.917 | 0.906 |
| 4m | 0.864 | 0.888 |
| 6m | 0.798 | 0.812 |
| 8m | 0.724 | 0.754 |
今週は、読み込んだ顔画像が登録していない顔のとき、誤認証されないかを各距離ごとに調べることと来週の大ゼミに向けたパワポを作成しようと思います。
説明変数をランダムに選んでモデルを作成するコードを作成した。
データを大量に増やした。
I ended up on a New Year's vacation for almost a month. It's been a great time. At the same time, research can't be slack.
I will continue to work on putting 3D geometry constraints and how to optimize depth maps.
(1)Writing the paperof ICIAE2024.
( 2 ) In the experiments about long term tracking, I found that the similarity between templates and current appearance is not reliable. Because what we need is the function that can identify whether two images are the same object, rather than the similarity distance between two images.
During tracking, the same object can have different appearance. The similarity distance between 0 and 1 are not suitable for judge.
So we should find another way in the field of image classification.
The experiements of re-detection with confidence score about long term tracking.
The confidence score is the biggest score to select the best location in each frame, which can be the basis of judge whether the target is lost. We can use the single confidence score or the sequenced confidence score to evaluate the tracking process.
Mixformer is a excellent short term trackers and Unicorn is a excellent glocal tracker. Our purpose aims to modify Mixformer to a long object trackers. So we want to add a re-detection mechanism. When the mechanism judge the tracking is failed, the running tracker will exchange to the global tracker to find the lost target object.
In this experiments, the re-detection mechanism exploit the confidence score to judge whether the target is lost.
Lasot is the benchmark of long term object tracking and average confidence score of mixformer in the lasot is 0.58 when IOU is zero.
The experiments are as follows:
lasot | Success | Precision | Norm Precision | Mixformer-base | 0.711 | 0.757 |0.740 | M_U_sc_30 | 0.713 | 0.761 |0.743 | M_U_sc_58 | 0.711 | 0.758 |0.742 | M_U_sc_sq_10_30 | 0.718 | 0.764 |0.749 | M_U_sc_sq_20_30 | 0.719 | 0.766 |0.749 | M_U_sc_sq_50_30 | 0.718 | 0.765 |0.747 | M_U_sc_sq_100_30 | 0.715 | 0.761 |0.745 | M_U_sc_sq_200_30 | 0.714 | 0.760 |0.743 | M_U_sc_psq_10_30 | 0.718 | 0.764 |0.748 | M_U_sc_psq_20_30 | 0.718 | 0.765 |0.748 | M_U_sc_sq_10_58 | 0.715 | 0.762 |0.745 | M_U_sc_sq_200_58 | 0.715 | 0.763 |0.745 |
Where M_U_sc_30 is the tracker using score under 0.3 and M_U_sc_58 is the tracker using score under 0.58. M_U_sc_sq_10_30 means that average ten confidence scores under 0.3. And Psq uses penalty.
The 0.3 may be more effective than 0.58. The best length of sequence may be 20. The penaly seems not effective. It’s too cumbersome to conduct more experiments on hyperparameters
In summary, we can see that exploiting confidence score to re-detect works but is not obvious. So in the next step, we can conduct experiemts on the similarity of templates and tracking object.
→わかってはいたがうまく判定できなかった。
良モデル作成には、今のところ自分のデータを使うしかない(飲酒前後30分でできる)
→少ないデータで学習し構築したモデルの方が精度が良かった。
学習データ少↓
学習データ多↓
実際に教室(5-2A)でどのくらいの距離まで認証されるのか試してみた。
中心窩画像処理のプログラミングを完成しました。中間領域の解像度を変換する距離を偏心度視力モデルの図から決めていこうと思います。